Statistical Research Questions: Five Examples for Quantitative Analysis
Table of contents, introduction.
How are statistical research questions for quantitative analysis written? This article provides five examples of statistical research questions that will allow statistical analysis to take place.
In quantitative research projects, writing statistical research questions requires a good understanding and the ability to discern the type of data that you will analyze. This knowledge is elemental in framing research questions that shall guide you in identifying the appropriate statistical test to use in your research.
Thus, before writing your statistical research questions and reading the examples in this article, read first the article that enumerates the four types of measurement scales . Knowing the four types of measurement scales will enable you to appreciate the formulation or structuring of research questions.

Five Examples of Statistical Research Questions
In writing the statistical research questions, I provide a topic that shows the variables of the study, the study description, and a link to the original scientific article to give you a glimpse of the real-world examples.
Topic 1: Physical Fitness and Academic Achievement
A study was conducted to determine the relationship between physical fitness and academic achievement. The subjects of the study include school children in urban schools.
Statistical Research Question No. 1
Is there a significant relationship between physical fitness and academic achievement?
To allow statistical analysis to take place, there is a need to define what is physical fitness, as well as academic achievement. The researchers measured physical fitness in terms of the number of physical fitness tests that the students passed during their physical education class. It’s simply counting the ‘number of PE tests passed.’
On the other hand, the researchers measured academic achievement in terms of a passing score in Mathematics and English. The variable is the number of passing scores in both Mathematics and English.
Given the statistical research question, the appropriate statistical test can be applied to determine the relationship. A Pearson correlation coefficient test will test the significance and degree of the relationship. But the more sophisticated higher level statistical test can be applied if there is a need to correlate with other variables.
In the particular study mentioned, the researchers used multivariate logistic regression analyses to assess the probability of passing the tests, controlling for students’ weight status, ethnicity, gender, grade, and socioeconomic status. For the novice researcher, this requires further study of multivariate (or many variables) statistical tests. You may study it on your own.
Most of what I discuss in the statistics articles I wrote came from self-study. It’s easier to understand concepts now as there are a lot of resource materials available online. Videos and ebooks from places like Youtube, Veoh, The Internet Archives, among others, provide free educational materials. Online education will be the norm of the future. I describe this situation in my post about Education 4.0 .
Topic 2: Climate Conditions and Consumption of Bottled Water
This study attempted to correlate climate conditions with the decision of people in Ecuador to consume bottled water, including the volume consumed. Specifically, the researchers investigated if the increase in average ambient temperature affects the consumption of bottled water.
Statistical Research Question No. 2
Is there a significant relationship between average temperature and amount of bottled water consumed?
Now, it’s easy to identify the statistical test to analyze the relationship between the two variables. You may refer to my previous post titled Parametric Statistics: Four Widely Used Parametric Tests and When to Use Them . Using the figure supplied in that article, the appropriate test to use is, again, Pearson’s Correlation Coefficient.
Source: Zapata (2021)
Topic 3: Nursing Home Staff Size and Number of COVID-19 Cases
Statistical research question no. 3.
Note that this study on COVID-19 looked into three variables, namely 1) number of unique employees working in skilled nursing homes, 2) number of weekly confirmed cases among residents and staff, and 3) number of weekly COVID-19 deaths among residents.
We call the variable number of unique employees the independent variable , and the other two variables ( number of weekly confirmed cases among residents and staff and number of weekly COVID-19 deaths among residents ) as the dependent variables .
A simple Pearson test may be used to correlate one variable with another variable. But the study used multiple variables. Hence, they produced regression models that show how multiple variables affect the outcome. Some of the variables in the study may be redundant, meaning, those variables may represent the same attribute of a population. Stepwise multiple regression models take care of those redundancies. Using this statistical test requires further study and experience.
Topic 4: Surrounding Greenness, Stress, and Memory
Scientific evidence has shown that surrounding greenness has multiple health-related benefits. Health benefits include better cognitive functioning or better intellectual activity such as thinking, reasoning, or remembering things. These findings, however, are not well understood. A study, therefore, analyzed the relationship between surrounding greenness and memory performance, with stress as a mediating variable.
Statistical Research Question No. 4
As this article is behind a paywall and we cannot see the full article, we can content ourselves with the knowledge that three major variables were explored in this study. These are 1) exposure to and use of natural environments, 2) stress, and 3) memory performance.
As you become more familiar and well-versed in identifying the variables you would like to investigate in your study, reading studies like this requires reading the method or methodology section. This section will tell you how the researchers measured the variables of their study. Knowing how those variables are quantified can help you design your research and formulate the appropriate statistical research questions.
Topic 5: Income and Happiness
This recent finding is an interesting read and is available online. Just click on the link I provide as the source below. The study sought to determine if income plays a role in people’s happiness across three age groups: young (18-30 years), middle (31-64 years), and old (65 or older). The literature review suggests that income has a positive effect on an individual’s sense of happiness. That’s because more money increases opportunities to fulfill dreams and buy more goods and services.
If you click on the link to the full text of the paper on pages 10 and 11, you will read that the researcher measured happiness using a 10-point scale. The scale was categorized into three namely, 1) unhappy, 2) happy, and 3) very happy.
An investigation was conducted to determine if the size of nursing home staff and the number of COVID-19 cases are correlated. Specifically, they looked into the number of unique employees working daily, and the outcomes include weekly counts of confirmed COVID-19 cases among residents and staff and weekly COVID-19 deaths among residents.
Statistical Research Question No. 5
Is there a significant relationship between income and happiness?
I do hope that upon reaching this part of the article, you are now well familiar on how to write statistical research questions. Practice makes perfect.
References:
Lega, C., Gidlow, C., Jones, M., Ellis, N., & Hurst, G. (2021). The relationship between surrounding greenness, stress and memory. Urban Forestry & Urban Greening , 59 , 126974.
Måseide, H. (2021). Income and Happiness: Does the relationship vary with age?
© P. A. Regoniel 12 October 2021 | Updated 08 January 2024
Related Posts
What is the topic sentence, paragraph unity (tspu) writing technique, how to use a mind map to prepare your research proposal, black wasp: 4 amazing facts, about the author, patrick regoniel, simplyeducate.me privacy policy.
Have a thesis expert improve your writing
Check your thesis for plagiarism in 10 minutes, generate your apa citations for free.
- Knowledge Base
The Beginner's Guide to Statistical Analysis | 5 Steps & Examples
Statistical analysis means investigating trends, patterns, and relationships using quantitative data . It is an important research tool used by scientists, governments, businesses, and other organisations.
To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process . You need to specify your hypotheses and make decisions about your research design, sample size, and sampling procedure.
After collecting data from your sample, you can organise and summarise the data using descriptive statistics . Then, you can use inferential statistics to formally test hypotheses and make estimates about the population. Finally, you can interpret and generalise your findings.
This article is a practical introduction to statistical analysis for students and researchers. We’ll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between variables.
Table of contents
Step 1: write your hypotheses and plan your research design, step 2: collect data from a sample, step 3: summarise your data with descriptive statistics, step 4: test hypotheses or make estimates with inferential statistics, step 5: interpret your results, frequently asked questions about statistics.
To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design.
Writing statistical hypotheses
The goal of research is often to investigate a relationship between variables within a population . You start with a prediction, and use statistical analysis to test that prediction.
A statistical hypothesis is a formal way of writing a prediction about a population. Every research prediction is rephrased into null and alternative hypotheses that can be tested using sample data.
While the null hypothesis always predicts no effect or no relationship between variables, the alternative hypothesis states your research prediction of an effect or relationship.
- Null hypothesis: A 5-minute meditation exercise will have no effect on math test scores in teenagers.
- Alternative hypothesis: A 5-minute meditation exercise will improve math test scores in teenagers.
- Null hypothesis: Parental income and GPA have no relationship with each other in college students.
- Alternative hypothesis: Parental income and GPA are positively correlated in college students.
Planning your research design
A research design is your overall strategy for data collection and analysis. It determines the statistical tests you can use to test your hypothesis later on.
First, decide whether your research will use a descriptive, correlational, or experimental design. Experiments directly influence variables, whereas descriptive and correlational studies only measure variables.
- In an experimental design , you can assess a cause-and-effect relationship (e.g., the effect of meditation on test scores) using statistical tests of comparison or regression.
- In a correlational design , you can explore relationships between variables (e.g., parental income and GPA) without any assumption of causality using correlation coefficients and significance tests.
- In a descriptive design , you can study the characteristics of a population or phenomenon (e.g., the prevalence of anxiety in U.S. college students) using statistical tests to draw inferences from sample data.
Your research design also concerns whether you’ll compare participants at the group level or individual level, or both.
- In a between-subjects design , you compare the group-level outcomes of participants who have been exposed to different treatments (e.g., those who performed a meditation exercise vs those who didn’t).
- In a within-subjects design , you compare repeated measures from participants who have participated in all treatments of a study (e.g., scores from before and after performing a meditation exercise).
- In a mixed (factorial) design , one variable is altered between subjects and another is altered within subjects (e.g., pretest and posttest scores from participants who either did or didn’t do a meditation exercise).
- Experimental
- Correlational
First, you’ll take baseline test scores from participants. Then, your participants will undergo a 5-minute meditation exercise. Finally, you’ll record participants’ scores from a second math test.
In this experiment, the independent variable is the 5-minute meditation exercise, and the dependent variable is the math test score from before and after the intervention. Example: Correlational research design In a correlational study, you test whether there is a relationship between parental income and GPA in graduating college students. To collect your data, you will ask participants to fill in a survey and self-report their parents’ incomes and their own GPA.
Measuring variables
When planning a research design, you should operationalise your variables and decide exactly how you will measure them.
For statistical analysis, it’s important to consider the level of measurement of your variables, which tells you what kind of data they contain:
- Categorical data represents groupings. These may be nominal (e.g., gender) or ordinal (e.g. level of language ability).
- Quantitative data represents amounts. These may be on an interval scale (e.g. test score) or a ratio scale (e.g. age).
Many variables can be measured at different levels of precision. For example, age data can be quantitative (8 years old) or categorical (young). If a variable is coded numerically (e.g., level of agreement from 1–5), it doesn’t automatically mean that it’s quantitative instead of categorical.
Identifying the measurement level is important for choosing appropriate statistics and hypothesis tests. For example, you can calculate a mean score with quantitative data, but not with categorical data.
In a research study, along with measures of your variables of interest, you’ll often collect data on relevant participant characteristics.
| Variable | Type of data |
|---|---|
| Age | Quantitative (ratio) |
| Gender | Categorical (nominal) |
| Race or ethnicity | Categorical (nominal) |
| Baseline test scores | Quantitative (interval) |
| Final test scores | Quantitative (interval) |
| Parental income | Quantitative (ratio) |
|---|---|
| GPA | Quantitative (interval) |

In most cases, it’s too difficult or expensive to collect data from every member of the population you’re interested in studying. Instead, you’ll collect data from a sample.
Statistical analysis allows you to apply your findings beyond your own sample as long as you use appropriate sampling procedures . You should aim for a sample that is representative of the population.
Sampling for statistical analysis
There are two main approaches to selecting a sample.
- Probability sampling: every member of the population has a chance of being selected for the study through random selection.
- Non-probability sampling: some members of the population are more likely than others to be selected for the study because of criteria such as convenience or voluntary self-selection.
In theory, for highly generalisable findings, you should use a probability sampling method. Random selection reduces sampling bias and ensures that data from your sample is actually typical of the population. Parametric tests can be used to make strong statistical inferences when data are collected using probability sampling.
But in practice, it’s rarely possible to gather the ideal sample. While non-probability samples are more likely to be biased, they are much easier to recruit and collect data from. Non-parametric tests are more appropriate for non-probability samples, but they result in weaker inferences about the population.
If you want to use parametric tests for non-probability samples, you have to make the case that:
- your sample is representative of the population you’re generalising your findings to.
- your sample lacks systematic bias.
Keep in mind that external validity means that you can only generalise your conclusions to others who share the characteristics of your sample. For instance, results from Western, Educated, Industrialised, Rich and Democratic samples (e.g., college students in the US) aren’t automatically applicable to all non-WEIRD populations.
If you apply parametric tests to data from non-probability samples, be sure to elaborate on the limitations of how far your results can be generalised in your discussion section .
Create an appropriate sampling procedure
Based on the resources available for your research, decide on how you’ll recruit participants.
- Will you have resources to advertise your study widely, including outside of your university setting?
- Will you have the means to recruit a diverse sample that represents a broad population?
- Do you have time to contact and follow up with members of hard-to-reach groups?
Your participants are self-selected by their schools. Although you’re using a non-probability sample, you aim for a diverse and representative sample. Example: Sampling (correlational study) Your main population of interest is male college students in the US. Using social media advertising, you recruit senior-year male college students from a smaller subpopulation: seven universities in the Boston area.
Calculate sufficient sample size
Before recruiting participants, decide on your sample size either by looking at other studies in your field or using statistics. A sample that’s too small may be unrepresentative of the sample, while a sample that’s too large will be more costly than necessary.
There are many sample size calculators online. Different formulas are used depending on whether you have subgroups or how rigorous your study should be (e.g., in clinical research). As a rule of thumb, a minimum of 30 units or more per subgroup is necessary.
To use these calculators, you have to understand and input these key components:
- Significance level (alpha): the risk of rejecting a true null hypothesis that you are willing to take, usually set at 5%.
- Statistical power : the probability of your study detecting an effect of a certain size if there is one, usually 80% or higher.
- Expected effect size : a standardised indication of how large the expected result of your study will be, usually based on other similar studies.
- Population standard deviation: an estimate of the population parameter based on a previous study or a pilot study of your own.
Once you’ve collected all of your data, you can inspect them and calculate descriptive statistics that summarise them.
Inspect your data
There are various ways to inspect your data, including the following:
- Organising data from each variable in frequency distribution tables .
- Displaying data from a key variable in a bar chart to view the distribution of responses.
- Visualising the relationship between two variables using a scatter plot .
By visualising your data in tables and graphs, you can assess whether your data follow a skewed or normal distribution and whether there are any outliers or missing data.
A normal distribution means that your data are symmetrically distributed around a center where most values lie, with the values tapering off at the tail ends.

In contrast, a skewed distribution is asymmetric and has more values on one end than the other. The shape of the distribution is important to keep in mind because only some descriptive statistics should be used with skewed distributions.
Extreme outliers can also produce misleading statistics, so you may need a systematic approach to dealing with these values.
Calculate measures of central tendency
Measures of central tendency describe where most of the values in a data set lie. Three main measures of central tendency are often reported:
- Mode : the most popular response or value in the data set.
- Median : the value in the exact middle of the data set when ordered from low to high.
- Mean : the sum of all values divided by the number of values.
However, depending on the shape of the distribution and level of measurement, only one or two of these measures may be appropriate. For example, many demographic characteristics can only be described using the mode or proportions, while a variable like reaction time may not have a mode at all.
Calculate measures of variability
Measures of variability tell you how spread out the values in a data set are. Four main measures of variability are often reported:
- Range : the highest value minus the lowest value of the data set.
- Interquartile range : the range of the middle half of the data set.
- Standard deviation : the average distance between each value in your data set and the mean.
- Variance : the square of the standard deviation.
Once again, the shape of the distribution and level of measurement should guide your choice of variability statistics. The interquartile range is the best measure for skewed distributions, while standard deviation and variance provide the best information for normal distributions.
Using your table, you should check whether the units of the descriptive statistics are comparable for pretest and posttest scores. For example, are the variance levels similar across the groups? Are there any extreme values? If there are, you may need to identify and remove extreme outliers in your data set or transform your data before performing a statistical test.
| Pretest scores | Posttest scores | |
|---|---|---|
| Mean | 68.44 | 75.25 |
| Standard deviation | 9.43 | 9.88 |
| Variance | 88.96 | 97.96 |
| Range | 36.25 | 45.12 |
| 30 | ||
From this table, we can see that the mean score increased after the meditation exercise, and the variances of the two scores are comparable. Next, we can perform a statistical test to find out if this improvement in test scores is statistically significant in the population. Example: Descriptive statistics (correlational study) After collecting data from 653 students, you tabulate descriptive statistics for annual parental income and GPA.
It’s important to check whether you have a broad range of data points. If you don’t, your data may be skewed towards some groups more than others (e.g., high academic achievers), and only limited inferences can be made about a relationship.
| Parental income (USD) | GPA | |
|---|---|---|
| Mean | 62,100 | 3.12 |
| Standard deviation | 15,000 | 0.45 |
| Variance | 225,000,000 | 0.16 |
| Range | 8,000–378,000 | 2.64–4.00 |
| 653 | ||
A number that describes a sample is called a statistic , while a number describing a population is called a parameter . Using inferential statistics , you can make conclusions about population parameters based on sample statistics.
Researchers often use two main methods (simultaneously) to make inferences in statistics.
- Estimation: calculating population parameters based on sample statistics.
- Hypothesis testing: a formal process for testing research predictions about the population using samples.
You can make two types of estimates of population parameters from sample statistics:
- A point estimate : a value that represents your best guess of the exact parameter.
- An interval estimate : a range of values that represent your best guess of where the parameter lies.
If your aim is to infer and report population characteristics from sample data, it’s best to use both point and interval estimates in your paper.
You can consider a sample statistic a point estimate for the population parameter when you have a representative sample (e.g., in a wide public opinion poll, the proportion of a sample that supports the current government is taken as the population proportion of government supporters).
There’s always error involved in estimation, so you should also provide a confidence interval as an interval estimate to show the variability around a point estimate.
A confidence interval uses the standard error and the z score from the standard normal distribution to convey where you’d generally expect to find the population parameter most of the time.
Hypothesis testing
Using data from a sample, you can test hypotheses about relationships between variables in the population. Hypothesis testing starts with the assumption that the null hypothesis is true in the population, and you use statistical tests to assess whether the null hypothesis can be rejected or not.
Statistical tests determine where your sample data would lie on an expected distribution of sample data if the null hypothesis were true. These tests give two main outputs:
- A test statistic tells you how much your data differs from the null hypothesis of the test.
- A p value tells you the likelihood of obtaining your results if the null hypothesis is actually true in the population.
Statistical tests come in three main varieties:
- Comparison tests assess group differences in outcomes.
- Regression tests assess cause-and-effect relationships between variables.
- Correlation tests assess relationships between variables without assuming causation.
Your choice of statistical test depends on your research questions, research design, sampling method, and data characteristics.
Parametric tests
Parametric tests make powerful inferences about the population based on sample data. But to use them, some assumptions must be met, and only some types of variables can be used. If your data violate these assumptions, you can perform appropriate data transformations or use alternative non-parametric tests instead.
A regression models the extent to which changes in a predictor variable results in changes in outcome variable(s).
- A simple linear regression includes one predictor variable and one outcome variable.
- A multiple linear regression includes two or more predictor variables and one outcome variable.
Comparison tests usually compare the means of groups. These may be the means of different groups within a sample (e.g., a treatment and control group), the means of one sample group taken at different times (e.g., pretest and posttest scores), or a sample mean and a population mean.
- A t test is for exactly 1 or 2 groups when the sample is small (30 or less).
- A z test is for exactly 1 or 2 groups when the sample is large.
- An ANOVA is for 3 or more groups.
The z and t tests have subtypes based on the number and types of samples and the hypotheses:
- If you have only one sample that you want to compare to a population mean, use a one-sample test .
- If you have paired measurements (within-subjects design), use a dependent (paired) samples test .
- If you have completely separate measurements from two unmatched groups (between-subjects design), use an independent (unpaired) samples test .
- If you expect a difference between groups in a specific direction, use a one-tailed test .
- If you don’t have any expectations for the direction of a difference between groups, use a two-tailed test .
The only parametric correlation test is Pearson’s r . The correlation coefficient ( r ) tells you the strength of a linear relationship between two quantitative variables.
However, to test whether the correlation in the sample is strong enough to be important in the population, you also need to perform a significance test of the correlation coefficient, usually a t test, to obtain a p value. This test uses your sample size to calculate how much the correlation coefficient differs from zero in the population.
You use a dependent-samples, one-tailed t test to assess whether the meditation exercise significantly improved math test scores. The test gives you:
- a t value (test statistic) of 3.00
- a p value of 0.0028
Although Pearson’s r is a test statistic, it doesn’t tell you anything about how significant the correlation is in the population. You also need to test whether this sample correlation coefficient is large enough to demonstrate a correlation in the population.
A t test can also determine how significantly a correlation coefficient differs from zero based on sample size. Since you expect a positive correlation between parental income and GPA, you use a one-sample, one-tailed t test. The t test gives you:
- a t value of 3.08
- a p value of 0.001
The final step of statistical analysis is interpreting your results.
Statistical significance
In hypothesis testing, statistical significance is the main criterion for forming conclusions. You compare your p value to a set significance level (usually 0.05) to decide whether your results are statistically significant or non-significant.
Statistically significant results are considered unlikely to have arisen solely due to chance. There is only a very low chance of such a result occurring if the null hypothesis is true in the population.
This means that you believe the meditation intervention, rather than random factors, directly caused the increase in test scores. Example: Interpret your results (correlational study) You compare your p value of 0.001 to your significance threshold of 0.05. With a p value under this threshold, you can reject the null hypothesis. This indicates a statistically significant correlation between parental income and GPA in male college students.
Note that correlation doesn’t always mean causation, because there are often many underlying factors contributing to a complex variable like GPA. Even if one variable is related to another, this may be because of a third variable influencing both of them, or indirect links between the two variables.
Effect size
A statistically significant result doesn’t necessarily mean that there are important real life applications or clinical outcomes for a finding.
In contrast, the effect size indicates the practical significance of your results. It’s important to report effect sizes along with your inferential statistics for a complete picture of your results. You should also report interval estimates of effect sizes if you’re writing an APA style paper .
With a Cohen’s d of 0.72, there’s medium to high practical significance to your finding that the meditation exercise improved test scores. Example: Effect size (correlational study) To determine the effect size of the correlation coefficient, you compare your Pearson’s r value to Cohen’s effect size criteria.
Decision errors
Type I and Type II errors are mistakes made in research conclusions. A Type I error means rejecting the null hypothesis when it’s actually true, while a Type II error means failing to reject the null hypothesis when it’s false.
You can aim to minimise the risk of these errors by selecting an optimal significance level and ensuring high power . However, there’s a trade-off between the two errors, so a fine balance is necessary.
Frequentist versus Bayesian statistics
Traditionally, frequentist statistics emphasises null hypothesis significance testing and always starts with the assumption of a true null hypothesis.
However, Bayesian statistics has grown in popularity as an alternative approach in the last few decades. In this approach, you use previous research to continually update your hypotheses based on your expectations and observations.
Bayes factor compares the relative strength of evidence for the null versus the alternative hypothesis rather than making a conclusion about rejecting the null hypothesis or not.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts, and meanings, use qualitative methods .
- If you want to analyse a large amount of readily available data, use secondary data. If you want data specific to your purposes with control over how they are generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Statistical analysis is the main method for analyzing quantitative research data . It uses probabilities and models to test predictions about a population from sample data.
Is this article helpful?
Other students also liked, a quick guide to experimental design | 5 steps & examples, controlled experiments | methods & examples of control, between-subjects design | examples, pros & cons, more interesting articles.
- Central Limit Theorem | Formula, Definition & Examples
- Central Tendency | Understanding the Mean, Median & Mode
- Correlation Coefficient | Types, Formulas & Examples
- Descriptive Statistics | Definitions, Types, Examples
- How to Calculate Standard Deviation (Guide) | Calculator & Examples
- How to Calculate Variance | Calculator, Analysis & Examples
- How to Find Degrees of Freedom | Definition & Formula
- How to Find Interquartile Range (IQR) | Calculator & Examples
- How to Find Outliers | Meaning, Formula & Examples
- How to Find the Geometric Mean | Calculator & Formula
- How to Find the Mean | Definition, Examples & Calculator
- How to Find the Median | Definition, Examples & Calculator
- How to Find the Range of a Data Set | Calculator & Formula
- Inferential Statistics | An Easy Introduction & Examples
- Levels of measurement: Nominal, ordinal, interval, ratio
- Missing Data | Types, Explanation, & Imputation
- Normal Distribution | Examples, Formulas, & Uses
- Null and Alternative Hypotheses | Definitions & Examples
- Poisson Distributions | Definition, Formula & Examples
- Skewness | Definition, Examples & Formula
- T-Distribution | What It Is and How To Use It (With Examples)
- The Standard Normal Distribution | Calculator, Examples & Uses
- Type I & Type II Errors | Differences, Examples, Visualizations
- Understanding Confidence Intervals | Easy Examples & Formulas
- Variability | Calculating Range, IQR, Variance, Standard Deviation
- What is Effect Size and Why Does It Matter? (Examples)
- What Is Interval Data? | Examples & Definition
- What Is Nominal Data? | Examples & Definition
- What Is Ordinal Data? | Examples & Definition
- What Is Ratio Data? | Examples & Definition
- What Is the Mode in Statistics? | Definition, Examples & Calculator
- What DataKleenr Can Do For You
- How DataKleenr Works
- DataKleenr Credits
- Ways to Earn
- What CorrelViz Can Do For You
- How CorrelViz Works
- CorrelViz Credits
- Book a Call
- The Hive – Home
- Course Pricing
- Membership Pricing
- Members Area
- Need Help Subscribing? Start Here
- How To Enrol on Our Courses
- Log in to The Hive
- Reset Hive Password
- The Captain’s Blog
- Discover Data
Discover Stats
- Discover Visualisation
Demystifying Statistical Tests: A Guide to Choosing the Right One
0 comments
Welcome to the fascinating world of statistical tests! If you've ever found yourself scratching your head when it comes to choosing the right statistical test for your data analysis, you're not alone. Statistical tests play a crucial role in making sense of data and drawing meaningful conclusions. In this section, we'll take a gentle dive into the basics of statistical tests, empowering you to make informed decisions.
Disclosure: This post contains affiliate links. This means that if you click one of the links and make a purchase we may receive a small commission at no extra cost to you. As an Amazon Associate we may earn an affiliate commission for purchases you make when using the links in this page.
You can find further details in our TCs
Introduction To Statistical Tests: Why Do We Need Statistical Tests Anyway?
Imagine you've conducted a survey to investigate the effectiveness of a new teaching method. You have gathered a bunch of data, but how do you know if the observed differences are statistically significant or just due to chance? Statistical tests come to the rescue! They help us determine whether the patterns or differences we observe in our data are real or simply random fluctuations.
Types of statistical tests: A world of possibilities!
There is a wide range of statistical tests available, each designed to answer specific research questions. Broadly speaking , statistical tests can be divided into two categories: parametric and non-parametric tests. Parametric tests assume that the data follows a specific distribution, while non-parametric tests make fewer assumptions about the data.
Choosing the right test: It's all about the question!
When it comes to selecting the appropriate statistical test, the first question you need to ask yourself is: What is the nature of your data and the research question you want to answer? Are you comparing means, testing for associations, or examining differences between groups? The answers to these questions will guide you in selecting the right test.
In the next section, we'll explore the different types of statistical tests in more detail, helping you gain a better understanding of their purposes and applications. So, get ready to embark on your statistical adventure, and remember, choosing the right test is like finding the perfect puzzle piece that completes the picture of your research!
Understanding the Purpose of Statistical Tests
Now that we've dipped our toes into the world of statistical tests, let's dive a little deeper and uncover their true purpose. You might be wondering, "Why do we even need statistical tests? Can't we just rely on intuition or gut feelings?" Great questions! Statistical tests bring objectivity and rigour to the table, helping us make sense of the data in a systematic and unbiased way.
Shedding light on uncertainty: Are the differences real?
Imagine you're comparing two groups, say, coffee drinkers and tea enthusiasts, and you want to determine if there is a significant difference in their average caffeine intake. Statistical tests act as our trusty detective, investigating whether the differences we observe are genuine or just due to random variation. They help us quantify uncertainty and determine if the results we obtain are reliable.
Making informed decisions based on evidence
In a world full of noise and randomness, statistical tests provide us with a reliable framework for decision-making . By using statistical tests, you can confidently answer questions like, "Does this new drug treatment really have a significant effect?" or "Is the advertising campaign truly boosting sales?" Statistical tests help you base your decisions on solid evidence rather than mere guesswork.
Guarding against biases and illusions
Our minds can play tricks on us, leading to biases and illusions in data interpretation. Statistical tests act as our loyal guards, protecting us from these pitfalls. They enable us to objectively evaluate the strength of evidence, helping us avoid jumping to premature conclusions or falling into the trap of misleading correlations.
In the next section, we'll explore the different types of statistical tests, each serving a unique purpose in answering specific research questions. So, buckle up and get ready to unlock the power of statistical tests! They will be your trusted allies in navigating the complex landscape of data analysis.
3 Simple Questions...
What's Stopping You Reaching YOUR Data Ninja Potential?
Answer 3 questions and we'll recommend the best route to
super-charge your data career
Types of Statistical Tests: Parametric vs. Non-Parametric
Now that you have a good grasp of why statistical tests are essential, let's embark on a journey to explore the exciting world of different statistical tests. Just like superheroes with unique powers, these tests come in various flavors, each designed to tackle specific research questions.
Parametric Tests: The superheroes of specific assumptions
Parametric tests are like superheroes who have a specific set of assumptions under their belt . They assume that the data follows a particular distribution, usually the normal distribution. These tests are powerful when the assumptions are met, allowing you to unlock a world of possibilities. Some common parametric tests include the t-test, analysis of variance (ANOVA), and linear regression.
Non-Parametric Tests: The versatile heroes who need fewer assumptions
Unlike their parametric counterparts, non-parametric tests are like versatile heroes who can handle data that doesn't quite fit the usual assumptions . These tests require fewer assumptions about the data distribution, making them more flexible in various situations. If you're working with ordinal or non-normally distributed data, non-parametric tests will come to your rescue. Examples include the Mann-Whitney U test, Kruskal-Wallis test, and Spearman's rank correlation.
Matched-Pair Tests: Uniting the power of related data
Sometimes, you'll encounter situations where you have paired or related data. This is where matched-pair tests swoop in to save the day! These tests allow you to compare measurements taken from the same subjects before and after an intervention or in a paired design. The paired t-test and Wilcoxon signed-rank test are popular choices for analyzing matched-pair data.
Choosing the right test: Your data's secret weapon
When it comes to deciding between parametric and non-parametric tests, it all boils down to the nature of your data and the assumptions you can reasonably make. If your data follows a normal distribution and the assumptions hold true, parametric tests offer great power. However, if your data is skewed or doesn't meet the assumptions, non-parametric tests step in as your flexible allies. Remember, choosing the right test is like finding the perfect tool for the job, so keep exploring and let your data guide you!
In the next section, we'll take a closer look at the factors you should consider when choosing a statistical test.
FREE Ultra-HD pdf Download
The hypothesis wheel.

Learn how to choose the correct statistical hypothesis test every time
Factors to Consider in Choosing a Statistical Test
As you continue your journey to become a master of statistical tests, it's important to know that choosing the right test is like selecting the perfect tool for a job. To guide you on this quest, let's explore some key factors to consider when making your decision. Ready? Let's dive in!
Nature of your data: What's in your dataset?
The first thing to consider is the nature of your data. Is it continuous, categorical, or ordinal? Understanding the type of data you have will narrow down your options and help you choose a test that is most suitable.
Research question: What are you trying to answer?
The specific question you want to answer will also play a crucial role in selecting the right test. Are you comparing means, testing for associations, or examining differences between groups? Clearly defining your research question will guide you toward the appropriate statistical test.
Assumptions: Can you meet the requirements?
Different tests have different assumptions, such as normality, independence, or equal variances. Consider whether your data meets these assumptions or if there are alternative tests available that are more robust to violations.
Sample size: How big is your dataset?
The size of your dataset matters too. Some tests require larger sample sizes to yield reliable results, while others are suitable for smaller samples. Take into account the number of observations you have and choose a test that is appropriate for your sample size.
By considering these factors, you'll be well-equipped to make an informed decision when choosing a statistical test. Remember, the goal is to find a test that aligns with your data, research question, and specific requirements.
Considerations for Sample Size and Data Distribution
As we delve deeper into the realm of statistical tests, it's important to consider two critical factors: sample size and data distribution. These factors can greatly influence the choice of the right statistical test for your analysis. So, let's dive in and uncover their significance together!
Sample Size: The power of numbers
The size of your dataset, or sample size, can have a profound impact on the statistical test you choose. A larger sample size generally provides more precise estimates and increases the power of your analysis, allowing you to detect smaller effects or differences. Keep in mind that some tests require a minimum sample size to yield meaningful results. So, if you have a smaller sample, it's crucial to choose a test that is appropriate for your data.
Data Distribution: The shape of your data
The distribution of your data plays a crucial role in determining the right statistical test. Many tests assume that the data follows a specific distribution, typically the normal distribution. If your data is normally distributed, you have a wide range of parametric tests at your disposal. However, if your data deviates from normality or is skewed, non-parametric tests may be more suitable. These tests make fewer assumptions about the data distribution, ensuring robust analysis even with non-normally distributed data.
Considering both sample size and data distribution will help you make an informed choice when selecting a statistical test. Remember, it's all about aligning the characteristics of your data with the appropriate analysis technique. So, be mindful of your sample size and take a close look at your data's distribution to embark on a successful statistical journey!
Common Statistical Tests and Their Applications
As you continue your quest to demystify statistical tests, it's time to shine a spotlight on some of the most common tests and their practical applications. Each test is like a valuable tool in your statistical toolkit, designed to answer specific research questions. So, let's explore these tests and discover their superpowers together!
t-test: Comparing means like a pro
The t-test is your go-to superhero when you want to compare means between two groups. Whether you're investigating if a new drug treatment is effective or examining the impact of different teaching methods, the t-test comes to your rescue, providing insights into whether the observed differences are statistically significant.
Analysis of Variance (ANOVA): Unlocking group differences
When you have more than two groups to compare, ANOVA swoops in to save the day! ANOVA helps you determine if there are significant differences among multiple groups. Whether you're comparing the performance of different age groups or testing the effects of different diets, ANOVA is your trusted ally.
Chi-square test: Unraveling associations
When you want to explore associations or relationships between categorical variables, the Chi-square test is your loyal companion. It helps you uncover whether there is a significant association between variables, such as investigating if there is a relationship between smoking habits and lung cancer incidence.
Correlation analysis: Unveiling connections
Correlation analysis allows you to measure the strength and direction of the relationship between two continuous variables. Whether you're examining the relationship between height and weight or analyzing the association between test scores and study time, correlation analysis provides valuable insights into the connection between variables.
By familiarizing yourself with these common statistical tests and their applications, you'll gain confidence in choosing the right tool for your data analysis needs. Remember, each test has its own unique superpower, so wield them wisely and unlock the secrets hidden within your data!
Step-by-Step Guide to Choosing the Right Statistical Test
Choosing the right statistical test can feel like navigating a maze, but fear not, for we're here to guide you through the process step-by-step. Let's uncover the secrets of selecting the perfect test for your analysis !
Step 1: Clearly define your research question
Start by defining your research question. What do you want to investigate? Are you comparing groups, examining associations, or exploring differences? Clarifying your research question will set the stage for choosing the appropriate statistical test.
Step 2: Identify your data type
Next, identify the type of data you're working with. Is it continuous, categorical, or ordinal? This will help narrow down the pool of potential tests. Continuous data involves measurements on a scale, categorical data consists of distinct categories, and ordinal data has an inherent order.
Step 3: Consider the assumptions
Now, consider the assumptions of each test. Some tests assume normality, equal variances, or independence. Evaluate whether your data meets these assumptions or if there are alternative tests that are more robust to violations.
Step 4: Evaluate sample size
Take a look at your sample size. Some tests require larger sample sizes to yield reliable results, while others can handle smaller samples. Consider the number of observations you have and choose a test appropriate for your sample size.
Step 5: Consult reliable resources
When in doubt, consult reliable resources like textbooks, online guides, or statistical experts. They can provide valuable insights and recommendations tailored to your specific research question and dataset.
By following these steps, you'll be well-equipped to make an informed decision when choosing the right statistical test. Remember, the process may require some trial and error, but with practice, you'll become a pro at selecting the perfect test for your data analysis needs.
Real-World Examples of Statistical Test Selection
Now that you've learned the basics of choosing the right statistical test, let's dive into some real-world examples where different tests come to the rescue. By examining these examples, you'll gain a better understanding of how statistical tests are applied in practical situations.
Example 1: A/B Testing for Website Optimization
Imagine you're a website owner and want to compare two different versions of your homepage to see which one leads to higher user engagement. In this case, a classic A/B test using a t-test would be your weapon of choice. By randomly assigning users to either the control group (original version) or the experimental group (new version), you can compare the mean engagement metrics and determine if there's a statistically significant difference.
Example 2: Customer Satisfaction across Age Groups
Suppose you work in market research and want to examine customer satisfaction levels across different age groups. To explore this, you can employ an analysis of variance (ANOVA). By surveying customers from various age groups and comparing their satisfaction ratings, ANOVA will help you uncover whether there are significant differences among the groups.
Example 3: Examining the Relationship between Variables
Let's say you're a researcher investigating the relationship between study time and exam scores among college students. To analyze this association, you can turn to correlation analysis. By calculating the correlation coefficient, such as Pearson's r, you can determine the strength and direction of the relationship between study time and exam scores.
By exploring these real-world examples, you can see how different statistical tests are applied to address specific research questions. Remember, these examples are just the tip of the iceberg, and there are countless scenarios where statistical tests can be used to uncover valuable insights. So, keep honing your statistical skills and get ready to tackle your own data challenges with confidence!

Common Mistakes to Avoid When Choosing a Statistical Test
As you navigate the world of statistical tests, it's important to be aware of common pitfalls that can trip you up when selecting the right test . Don't worry, though—we've got your back! Let's shine a light on some of these common mistakes and help you avoid them like a pro.
Mistake 1: Ignoring the data type
One common blunder is overlooking the type of data you have. Remember to identify whether your data is continuous, categorical, or ordinal. Choosing a test that is inappropriate for your data type can lead to inaccurate results.
Mistake 2: Neglecting the assumptions
Assumptions matter! Ignoring the assumptions of a statistical test can undermine the validity of your analysis. Always check if your data meets the assumptions, such as normality or independence, and consider alternative tests if needed.
Mistake 3: Using the wrong sample size
Sample size matters! Using a test that requires a larger sample size when you have a smaller one can lead to unreliable results. Ensure that the test you choose is appropriate for the number of observations you have.
Mistake 4: Relying solely on p-values
While p-values are important, solely relying on them can be misleading. Remember to consider effect sizes, confidence intervals, and practical significance to gain a comprehensive understanding of your results.
Mistake 5: Failing to seek guidance
Don't hesitate to seek guidance! Consulting statistical resources, textbooks, or experts can provide invaluable insights and help you navigate through complex scenarios.
By avoiding these common mistakes, you'll be well on your way to selecting the right statistical test with confidence. Remember, even seasoned statisticians make errors, but learning from them is key to growth. So, stay curious, be vigilant, and keep honing your statistical skills. You've got this!
Conclusion: Empowering Yourself to Choose the Right Statistical Test
Congratulations! You've reached the end of our journey together in demystifying statistical tests. By now, you've gained a solid understanding of the key factors to consider when selecting the right test for your data analysis needs. It's time to reflect on what you've learned and embrace your newfound power to make informed decisions. Let's wrap it up!
Trust your knowledge and intuition
You've learned the foundations of statistical tests, from understanding their purpose to identifying different types and considering sample size and data distribution. Trust in the knowledge you've acquired and let your intuition guide you as you embark on future statistical endeavours.
Embrace the iterative process
Remember, choosing the right statistical test is often an iterative process. It may involve trial and error, refining your approach, and seeking guidance along the way. Embrace the learning process and don't be discouraged by setbacks. Each step you take will bring you closer to finding the perfect test for your analysis.
Stay curious and keep learning
Statistical tests are a vast and ever-evolving field. Embrace your curiosity and continue expanding your statistical knowledge. Explore advanced tests, new methodologies, and emerging research to deepen your understanding and broaden your statistical toolkit.
Share your knowledge and help others
As you become more proficient in choosing the right statistical test, share your knowledge with others. Help fellow beginners navigate the statistical landscape and empower them to make informed decisions. Together, we can demystify statistical tests and foster a community of data-driven thinkers.
Remember, statistical tests are powerful tools that enable you to unlock insights and make evidence-based decisions. By empowering yourself with the knowledge and skills to choose the right test, you become the master of your data. So, go forth, explore, and unleash the full potential of statistical tests in your data analysis endeavors. Happy testing!
chi-squared test, fisher's exact test, hypothesis testing, statistics, stats

About the Author
Lee Baker is an award-winning software creator that lives behind a keyboard in a darkened room. Illuminated only by the light from his monitor, he aspires to finding the light switch. With decades of experience in science, statistics and artificial intelligence, he has a passion for telling stories with data. His mission is to help you discover your inner Data Ninja!
You may also like
45+ awesome gifts for data scientists, statisticians and other geeks, computational statistics is the new holy grail – experts, 3 crucial tips for data processing and analysis, correlation is not causation – pirates prove it, cracking chi-square tests: step-by-step, chi-square test: the key to categorical analysis.
Educational resources and simple solutions for your research journey

What is Quantitative Research? Definition, Methods, Types, and Examples

If you’re wondering what is quantitative research and whether this methodology works for your research study, you’re not alone. If you want a simple quantitative research definition , then it’s enough to say that this is a method undertaken by researchers based on their study requirements. However, to select the most appropriate research for their study type, researchers should know all the methods available.
Selecting the right research method depends on a few important criteria, such as the research question, study type, time, costs, data availability, and availability of respondents. There are two main types of research methods— quantitative research and qualitative research. The purpose of quantitative research is to validate or test a theory or hypothesis and that of qualitative research is to understand a subject or event or identify reasons for observed patterns.
Quantitative research methods are used to observe events that affect a particular group of individuals, which is the sample population. In this type of research, diverse numerical data are collected through various methods and then statistically analyzed to aggregate the data, compare them, or show relationships among the data. Quantitative research methods broadly include questionnaires, structured observations, and experiments.
Here are two quantitative research examples:
- Satisfaction surveys sent out by a company regarding their revamped customer service initiatives. Customers are asked to rate their experience on a rating scale of 1 (poor) to 5 (excellent).
- A school has introduced a new after-school program for children, and a few months after commencement, the school sends out feedback questionnaires to the parents of the enrolled children. Such questionnaires usually include close-ended questions that require either definite answers or a Yes/No option. This helps in a quick, overall assessment of the program’s outreach and success.

Table of Contents
What is quantitative research ? 1,2
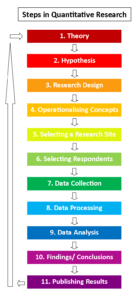
The steps shown in the figure can be grouped into the following broad steps:
- Theory : Define the problem area or area of interest and create a research question.
- Hypothesis : Develop a hypothesis based on the research question. This hypothesis will be tested in the remaining steps.
- Research design : In this step, the most appropriate quantitative research design will be selected, including deciding on the sample size, selecting respondents, identifying research sites, if any, etc.
- Data collection : This process could be extensive based on your research objective and sample size.
- Data analysis : Statistical analysis is used to analyze the data collected. The results from the analysis help in either supporting or rejecting your hypothesis.
- Present results : Based on the data analysis, conclusions are drawn, and results are presented as accurately as possible.
Quantitative research characteristics 4
- Large sample size : This ensures reliability because this sample represents the target population or market. Due to the large sample size, the outcomes can be generalized to the entire population as well, making this one of the important characteristics of quantitative research .
- Structured data and measurable variables: The data are numeric and can be analyzed easily. Quantitative research involves the use of measurable variables such as age, salary range, highest education, etc.
- Easy-to-use data collection methods : The methods include experiments, controlled observations, and questionnaires and surveys with a rating scale or close-ended questions, which require simple and to-the-point answers; are not bound by geographical regions; and are easy to administer.
- Data analysis : Structured and accurate statistical analysis methods using software applications such as Excel, SPSS, R. The analysis is fast, accurate, and less effort intensive.
- Reliable : The respondents answer close-ended questions, their responses are direct without ambiguity and yield numeric outcomes, which are therefore highly reliable.
- Reusable outcomes : This is one of the key characteristics – outcomes of one research can be used and replicated in other research as well and is not exclusive to only one study.
Quantitative research methods 5
Quantitative research methods are classified into two types—primary and secondary.
Primary quantitative research method:
In this type of quantitative research , data are directly collected by the researchers using the following methods.
– Survey research : Surveys are the easiest and most commonly used quantitative research method . They are of two types— cross-sectional and longitudinal.
->Cross-sectional surveys are specifically conducted on a target population for a specified period, that is, these surveys have a specific starting and ending time and researchers study the events during this period to arrive at conclusions. The main purpose of these surveys is to describe and assess the characteristics of a population. There is one independent variable in this study, which is a common factor applicable to all participants in the population, for example, living in a specific city, diagnosed with a specific disease, of a certain age group, etc. An example of a cross-sectional survey is a study to understand why individuals residing in houses built before 1979 in the US are more susceptible to lead contamination.
->Longitudinal surveys are conducted at different time durations. These surveys involve observing the interactions among different variables in the target population, exposing them to various causal factors, and understanding their effects across a longer period. These studies are helpful to analyze a problem in the long term. An example of a longitudinal study is the study of the relationship between smoking and lung cancer over a long period.
– Descriptive research : Explains the current status of an identified and measurable variable. Unlike other types of quantitative research , a hypothesis is not needed at the beginning of the study and can be developed even after data collection. This type of quantitative research describes the characteristics of a problem and answers the what, when, where of a problem. However, it doesn’t answer the why of the problem and doesn’t explore cause-and-effect relationships between variables. Data from this research could be used as preliminary data for another study. Example: A researcher undertakes a study to examine the growth strategy of a company. This sample data can be used by other companies to determine their own growth strategy.

– Correlational research : This quantitative research method is used to establish a relationship between two variables using statistical analysis and analyze how one affects the other. The research is non-experimental because the researcher doesn’t control or manipulate any of the variables. At least two separate sample groups are needed for this research. Example: Researchers studying a correlation between regular exercise and diabetes.
– Causal-comparative research : This type of quantitative research examines the cause-effect relationships in retrospect between a dependent and independent variable and determines the causes of the already existing differences between groups of people. This is not a true experiment because it doesn’t assign participants to groups randomly. Example: To study the wage differences between men and women in the same role. For this, already existing wage information is analyzed to understand the relationship.
– Experimental research : This quantitative research method uses true experiments or scientific methods for determining a cause-effect relation between variables. It involves testing a hypothesis through experiments, in which one or more independent variables are manipulated and then their effect on dependent variables are studied. Example: A researcher studies the importance of a drug in treating a disease by administering the drug in few patients and not administering in a few.
The following data collection methods are commonly used in primary quantitative research :
- Sampling : The most common type is probability sampling, in which a sample is chosen from a larger population using some form of random selection, that is, every member of the population has an equal chance of being selected. The different types of probability sampling are—simple random, systematic, stratified, and cluster sampling.
- Interviews : These are commonly telephonic or face-to-face.
- Observations : Structured observations are most commonly used in quantitative research . In this method, researchers make observations about specific behaviors of individuals in a structured setting.
- Document review : Reviewing existing research or documents to collect evidence for supporting the quantitative research .
- Surveys and questionnaires : Surveys can be administered both online and offline depending on the requirement and sample size.
The data collected can be analyzed in several ways in quantitative research , as listed below:
- Cross-tabulation —Uses a tabular format to draw inferences among collected data
- MaxDiff analysis —Gauges the preferences of the respondents
- TURF analysis —Total Unduplicated Reach and Frequency Analysis; helps in determining the market strategy for a business
- Gap analysis —Identify gaps in attaining the desired results
- SWOT analysis —Helps identify strengths, weaknesses, opportunities, and threats of a product, service, or organization
- Text analysis —Used for interpreting unstructured data
Secondary quantitative research methods :
This method involves conducting research using already existing or secondary data. This method is less effort intensive and requires lesser time. However, researchers should verify the authenticity and recency of the sources being used and ensure their accuracy.
The main sources of secondary data are:
- The Internet
- Government and non-government sources
- Public libraries
- Educational institutions
- Commercial information sources such as newspapers, journals, radio, TV

When to use quantitative research 6
Here are some simple ways to decide when to use quantitative research . Use quantitative research to:
- recommend a final course of action
- find whether a consensus exists regarding a particular subject
- generalize results to a larger population
- determine a cause-and-effect relationship between variables
- describe characteristics of specific groups of people
- test hypotheses and examine specific relationships
- identify and establish size of market segments
A research case study to understand when to use quantitative research 7
Context: A study was undertaken to evaluate a major innovation in a hospital’s design, in terms of workforce implications and impact on patient and staff experiences of all single-room hospital accommodations. The researchers undertook a mixed methods approach to answer their research questions. Here, we focus on the quantitative research aspect.
Research questions : What are the advantages and disadvantages for the staff as a result of the hospital’s move to the new design with all single-room accommodations? Did the move affect staff experience and well-being and improve their ability to deliver high-quality care?
Method: The researchers obtained quantitative data from three sources:
- Staff activity (task time distribution): Each staff member was shadowed by a researcher who observed each task undertaken by the staff, and logged the time spent on each activity.
- Staff travel distances : The staff were requested to wear pedometers, which recorded the distances covered.
- Staff experience surveys : Staff were surveyed before and after the move to the new hospital design.
Results of quantitative research : The following observations were made based on quantitative data analysis:
- The move to the new design did not result in a significant change in the proportion of time spent on different activities.
- Staff activity events observed per session were higher after the move, and direct care and professional communication events per hour decreased significantly, suggesting fewer interruptions and less fragmented care.
- A significant increase in medication tasks among the recorded events suggests that medication administration was integrated into patient care activities.
- Travel distances increased for all staff, with highest increases for staff in the older people’s ward and surgical wards.
- Ratings for staff toilet facilities, locker facilities, and space at staff bases were higher but those for social interaction and natural light were lower.
Advantages of quantitative research 1,2
When choosing the right research methodology, also consider the advantages of quantitative research and how it can impact your study.
- Quantitative research methods are more scientific and rational. They use quantifiable data leading to objectivity in the results and avoid any chances of ambiguity.
- This type of research uses numeric data so analysis is relatively easier .
- In most cases, a hypothesis is already developed and quantitative research helps in testing and validatin g these constructed theories based on which researchers can make an informed decision about accepting or rejecting their theory.
- The use of statistical analysis software ensures quick analysis of large volumes of data and is less effort intensive.
- Higher levels of control can be applied to the research so the chances of bias can be reduced.
- Quantitative research is based on measured value s, facts, and verifiable information so it can be easily checked or replicated by other researchers leading to continuity in scientific research.
Disadvantages of quantitative research 1,2
Quantitative research may also be limiting; take a look at the disadvantages of quantitative research.
- Experiments are conducted in controlled settings instead of natural settings and it is possible for researchers to either intentionally or unintentionally manipulate the experiment settings to suit the results they desire.
- Participants must necessarily give objective answers (either one- or two-word, or yes or no answers) and the reasons for their selection or the context are not considered.
- Inadequate knowledge of statistical analysis methods may affect the results and their interpretation.
- Although statistical analysis indicates the trends or patterns among variables, the reasons for these observed patterns cannot be interpreted and the research may not give a complete picture.
- Large sample sizes are needed for more accurate and generalizable analysis .
- Quantitative research cannot be used to address complex issues.

Frequently asked questions on quantitative research
Q: What is the difference between quantitative research and qualitative research? 1
A: The following table lists the key differences between quantitative research and qualitative research, some of which may have been mentioned earlier in the article.
| Purpose and design | ||
| Research question | ||
| Sample size | Large | Small |
| Data | ||
| Data collection method | Experiments, controlled observations, questionnaires and surveys with a rating scale or close-ended questions. The methods can be experimental, quasi-experimental, descriptive, or correlational. | Semi-structured interviews/surveys with open-ended questions, document study/literature reviews, focus groups, case study research, ethnography |
| Data analysis |
Q: What is the difference between reliability and validity? 8,9
A: The term reliability refers to the consistency of a research study. For instance, if a food-measuring weighing scale gives different readings every time the same quantity of food is measured then that weighing scale is not reliable. If the findings in a research study are consistent every time a measurement is made, then the study is considered reliable. However, it is usually unlikely to obtain the exact same results every time because some contributing variables may change. In such cases, a correlation coefficient is used to assess the degree of reliability. A strong positive correlation between the results indicates reliability.
Validity can be defined as the degree to which a tool actually measures what it claims to measure. It helps confirm the credibility of your research and suggests that the results may be generalizable. In other words, it measures the accuracy of the research.
The following table gives the key differences between reliability and validity.
| Importance | Refers to the consistency of a measure | Refers to the accuracy of a measure |
| Ease of achieving | Easier, yields results faster | Involves more analysis, more difficult to achieve |
| Assessment method | By examining the consistency of outcomes over time, between various observers, and within the test | By comparing the accuracy of the results with accepted theories and other measurements of the same idea |
| Relationship | Unreliable measurements typically cannot be valid | Valid measurements are also reliable |
| Types | Test-retest reliability, internal consistency, inter-rater reliability | Content validity, criterion validity, face validity, construct validity |
Q: What is mixed methods research? 10
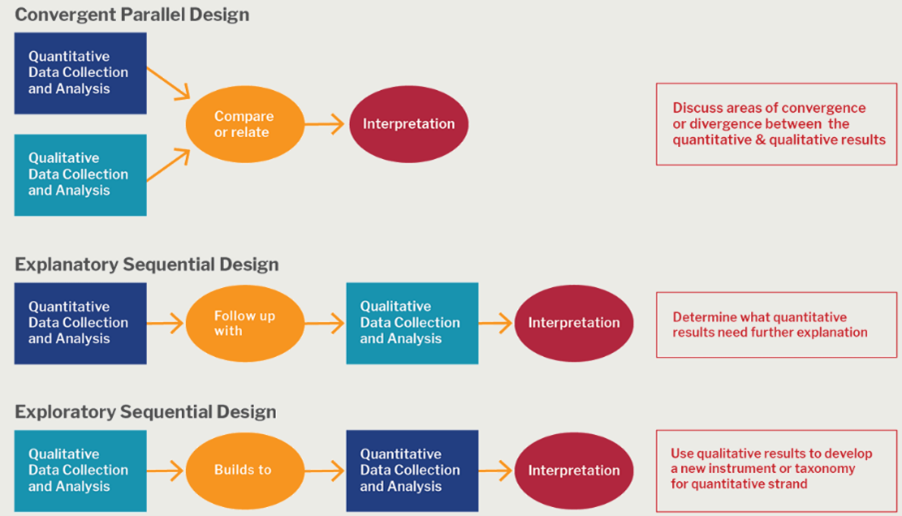
A: A mixed methods approach combines the characteristics of both quantitative research and qualitative research in the same study. This method allows researchers to validate their findings, verify if the results observed using both methods are complementary, and explain any unexpected results obtained from one method by using the other method. A mixed methods research design is useful in case of research questions that cannot be answered by either quantitative research or qualitative research alone. However, this method could be more effort- and cost-intensive because of the requirement of more resources. The figure 3 shows some basic mixed methods research designs that could be used.
Thus, quantitative research is the appropriate method for testing your hypotheses and can be used either alone or in combination with qualitative research per your study requirements. We hope this article has provided an insight into the various facets of quantitative research , including its different characteristics, advantages, and disadvantages, and a few tips to quickly understand when to use this research method.
References
- Qualitative vs quantitative research: Differences, examples, & methods. Simply Psychology. Accessed Feb 28, 2023. https://simplypsychology.org/qualitative-quantitative.html#Quantitative-Research
- Your ultimate guide to quantitative research. Qualtrics. Accessed February 28, 2023. https://www.qualtrics.com/uk/experience-management/research/quantitative-research/
- The steps of quantitative research. Revise Sociology. Accessed March 1, 2023. https://revisesociology.com/2017/11/26/the-steps-of-quantitative-research/
- What are the characteristics of quantitative research? Marketing91. Accessed March 1, 2023. https://www.marketing91.com/characteristics-of-quantitative-research/
- Quantitative research: Types, characteristics, methods, & examples. ProProfs Survey Maker. Accessed February 28, 2023. https://www.proprofssurvey.com/blog/quantitative-research/#Characteristics_of_Quantitative_Research
- Qualitative research isn’t as scientific as quantitative methods. Kmusial blog. Accessed March 5, 2023. https://kmusial.wordpress.com/2011/11/25/qualitative-research-isnt-as-scientific-as-quantitative-methods/
- Maben J, Griffiths P, Penfold C, et al. Evaluating a major innovation in hospital design: workforce implications and impact on patient and staff experiences of all single room hospital accommodation. Southampton (UK): NIHR Journals Library; 2015 Feb. (Health Services and Delivery Research, No. 3.3.) Chapter 5, Case study quantitative data findings. Accessed March 6, 2023. https://www.ncbi.nlm.nih.gov/books/NBK274429/
- McLeod, S. A. (2007). What is reliability? Simply Psychology. www.simplypsychology.org/reliability.html
- Reliability vs validity: Differences & examples. Accessed March 5, 2023. https://statisticsbyjim.com/basics/reliability-vs-validity/
- Mixed methods research. Community Engagement Program. Harvard Catalyst. Accessed February 28, 2023. https://catalyst.harvard.edu/community-engagement/mmr
Editage All Access is a subscription-based platform that unifies the best AI tools and services designed to speed up, simplify, and streamline every step of a researcher’s journey. The Editage All Access Pack is a one-of-a-kind subscription that unlocks full access to an AI writing assistant, literature recommender, journal finder, scientific illustration tool, and exclusive discounts on professional publication services from Editage.
Based on 22+ years of experience in academia, Editage All Access empowers researchers to put their best research forward and move closer to success. Explore our top AI Tools pack, AI Tools + Publication Services pack, or Build Your Own Plan. Find everything a researcher needs to succeed, all in one place – Get All Access now starting at just $14 a month !
Related Posts

What are the Best Research Funding Sources

Inductive vs. Deductive Research Approach
Quant Analysis 101: Descriptive Statistics
Everything You Need To Get Started (With Examples)
By: Derek Jansen (MBA) | Reviewers: Kerryn Warren (PhD) | October 2023
If you’re new to quantitative data analysis , one of the first terms you’re likely to hear being thrown around is descriptive statistics. In this post, we’ll unpack the basics of descriptive statistics, using straightforward language and loads of examples . So grab a cup of coffee and let’s crunch some numbers!
Overview: Descriptive Statistics
What are descriptive statistics.
- Descriptive vs inferential statistics
- Why the descriptives matter
- The “ Big 7 ” descriptive statistics
- Key takeaways
At the simplest level, descriptive statistics summarise and describe relatively basic but essential features of a quantitative dataset – for example, a set of survey responses. They provide a snapshot of the characteristics of your dataset and allow you to better understand, roughly, how the data are “shaped” (more on this later). For example, a descriptive statistic could include the proportion of males and females within a sample or the percentages of different age groups within a population.
Another common descriptive statistic is the humble average (which in statistics-talk is called the mean ). For example, if you undertook a survey and asked people to rate their satisfaction with a particular product on a scale of 1 to 10, you could then calculate the average rating. This is a very basic statistic, but as you can see, it gives you some idea of how this data point is shaped .

What about inferential statistics?
Now, you may have also heard the term inferential statistics being thrown around, and you’re probably wondering how that’s different from descriptive statistics. Simply put, descriptive statistics describe and summarise the sample itself , while inferential statistics use the data from a sample to make inferences or predictions about a population .
Put another way, descriptive statistics help you understand your dataset , while inferential statistics help you make broader statements about the population , based on what you observe within the sample. If you’re keen to learn more, we cover inferential stats in another post , or you can check out the explainer video below.
Why do descriptive statistics matter?
While descriptive statistics are relatively simple from a mathematical perspective, they play a very important role in any research project . All too often, students skim over the descriptives and run ahead to the seemingly more exciting inferential statistics, but this can be a costly mistake.
The reason for this is that descriptive statistics help you, as the researcher, comprehend the key characteristics of your sample without getting lost in vast amounts of raw data. In doing so, they provide a foundation for your quantitative analysis . Additionally, they enable you to quickly identify potential issues within your dataset – for example, suspicious outliers, missing responses and so on. Just as importantly, descriptive statistics inform the decision-making process when it comes to choosing which inferential statistics you’ll run, as each inferential test has specific requirements regarding the shape of the data.
Long story short, it’s essential that you take the time to dig into your descriptive statistics before looking at more “advanced” inferentials. It’s also worth noting that, depending on your research aims and questions, descriptive stats may be all that you need in any case . So, don’t discount the descriptives!

The “Big 7” descriptive statistics
With the what and why out of the way, let’s take a look at the most common descriptive statistics. Beyond the counts, proportions and percentages we mentioned earlier, we have what we call the “Big 7” descriptives. These can be divided into two categories – measures of central tendency and measures of dispersion.
Measures of central tendency
True to the name, measures of central tendency describe the centre or “middle section” of a dataset. In other words, they provide some indication of what a “typical” data point looks like within a given dataset. The three most common measures are:
The mean , which is the mathematical average of a set of numbers – in other words, the sum of all numbers divided by the count of all numbers.
The median , which is the middlemost number in a set of numbers, when those numbers are ordered from lowest to highest.
The mode , which is the most frequently occurring number in a set of numbers (in any order). Naturally, a dataset can have one mode, no mode (no number occurs more than once) or multiple modes.
To make this a little more tangible, let’s look at a sample dataset, along with the corresponding mean, median and mode. This dataset reflects the service ratings (on a scale of 1 – 10) from 15 customers.

As you can see, the mean of 5.8 is the average rating across all 15 customers. Meanwhile, 6 is the median . In other words, if you were to list all the responses in order from low to high, Customer 8 would be in the middle (with their service rating being 6). Lastly, the number 5 is the most frequent rating (appearing 3 times), making it the mode.
Together, these three descriptive statistics give us a quick overview of how these customers feel about the service levels at this business. In other words, most customers feel rather lukewarm and there’s certainly room for improvement. From a more statistical perspective, this also means that the data tend to cluster around the 5-6 mark , since the mean and the median are fairly close to each other.
To take this a step further, let’s look at the frequency distribution of the responses . In other words, let’s count how many times each rating was received, and then plot these counts onto a bar chart.

As you can see, the responses tend to cluster toward the centre of the chart , creating something of a bell-shaped curve. In statistical terms, this is called a normal distribution .
As you delve into quantitative data analysis, you’ll find that normal distributions are very common , but they’re certainly not the only type of distribution. In some cases, the data can lean toward the left or the right of the chart (i.e., toward the low end or high end). This lean is reflected by a measure called skewness , and it’s important to pay attention to this when you’re analysing your data, as this will have an impact on what types of inferential statistics you can use on your dataset.

Measures of dispersion
While the measures of central tendency provide insight into how “centred” the dataset is, it’s also important to understand how dispersed that dataset is . In other words, to what extent the data cluster toward the centre – specifically, the mean. In some cases, the majority of the data points will sit very close to the centre, while in other cases, they’ll be scattered all over the place. Enter the measures of dispersion, of which there are three:
Range , which measures the difference between the largest and smallest number in the dataset. In other words, it indicates how spread out the dataset really is.
Variance , which measures how much each number in a dataset varies from the mean (average). More technically, it calculates the average of the squared differences between each number and the mean. A higher variance indicates that the data points are more spread out , while a lower variance suggests that the data points are closer to the mean.
Standard deviation , which is the square root of the variance . It serves the same purposes as the variance, but is a bit easier to interpret as it presents a figure that is in the same unit as the original data . You’ll typically present this statistic alongside the means when describing the data in your research.
Again, let’s look at our sample dataset to make this all a little more tangible.

As you can see, the range of 8 reflects the difference between the highest rating (10) and the lowest rating (2). The standard deviation of 2.18 tells us that on average, results within the dataset are 2.18 away from the mean (of 5.8), reflecting a relatively dispersed set of data .
For the sake of comparison, let’s look at another much more tightly grouped (less dispersed) dataset.

As you can see, all the ratings lay between 5 and 8 in this dataset, resulting in a much smaller range, variance and standard deviation . You might also notice that the data are clustered toward the right side of the graph – in other words, the data are skewed. If we calculate the skewness for this dataset, we get a result of -0.12, confirming this right lean.
In summary, range, variance and standard deviation all provide an indication of how dispersed the data are . These measures are important because they help you interpret the measures of central tendency within context . In other words, if your measures of dispersion are all fairly high numbers, you need to interpret your measures of central tendency with some caution , as the results are not particularly centred. Conversely, if the data are all tightly grouped around the mean (i.e., low dispersion), the mean becomes a much more “meaningful” statistic).
Key Takeaways
We’ve covered quite a bit of ground in this post. Here are the key takeaways:
- Descriptive statistics, although relatively simple, are a critically important part of any quantitative data analysis.
- Measures of central tendency include the mean (average), median and mode.
- Skewness indicates whether a dataset leans to one side or another
- Measures of dispersion include the range, variance and standard deviation
If you’d like hands-on help with your descriptive statistics (or any other aspect of your research project), check out our private coaching service , where we hold your hand through each step of the research journey.

Psst… there’s more!
This post is an extract from our bestselling short course, Methodology Bootcamp . If you want to work smart, you don't want to miss this .

Good day. May I ask about where I would be able to find the statistics cheat sheet?

Right above you comment 🙂

Good job. you saved me

Brilliant and well explained. So much information explained clearly!
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- v.53(4); 2010 Aug
Research questions, hypotheses and objectives
Patricia farrugia.
* Michael G. DeGroote School of Medicine, the
Bradley A. Petrisor
† Division of Orthopaedic Surgery and the
Forough Farrokhyar
‡ Departments of Surgery and
§ Clinical Epidemiology and Biostatistics, McMaster University, Hamilton, Ont
Mohit Bhandari
There is an increasing familiarity with the principles of evidence-based medicine in the surgical community. As surgeons become more aware of the hierarchy of evidence, grades of recommendations and the principles of critical appraisal, they develop an increasing familiarity with research design. Surgeons and clinicians are looking more and more to the literature and clinical trials to guide their practice; as such, it is becoming a responsibility of the clinical research community to attempt to answer questions that are not only well thought out but also clinically relevant. The development of the research question, including a supportive hypothesis and objectives, is a necessary key step in producing clinically relevant results to be used in evidence-based practice. A well-defined and specific research question is more likely to help guide us in making decisions about study design and population and subsequently what data will be collected and analyzed. 1
Objectives of this article
In this article, we discuss important considerations in the development of a research question and hypothesis and in defining objectives for research. By the end of this article, the reader will be able to appreciate the significance of constructing a good research question and developing hypotheses and research objectives for the successful design of a research study. The following article is divided into 3 sections: research question, research hypothesis and research objectives.
Research question
Interest in a particular topic usually begins the research process, but it is the familiarity with the subject that helps define an appropriate research question for a study. 1 Questions then arise out of a perceived knowledge deficit within a subject area or field of study. 2 Indeed, Haynes suggests that it is important to know “where the boundary between current knowledge and ignorance lies.” 1 The challenge in developing an appropriate research question is in determining which clinical uncertainties could or should be studied and also rationalizing the need for their investigation.
Increasing one’s knowledge about the subject of interest can be accomplished in many ways. Appropriate methods include systematically searching the literature, in-depth interviews and focus groups with patients (and proxies) and interviews with experts in the field. In addition, awareness of current trends and technological advances can assist with the development of research questions. 2 It is imperative to understand what has been studied about a topic to date in order to further the knowledge that has been previously gathered on a topic. Indeed, some granting institutions (e.g., Canadian Institute for Health Research) encourage applicants to conduct a systematic review of the available evidence if a recent review does not already exist and preferably a pilot or feasibility study before applying for a grant for a full trial.
In-depth knowledge about a subject may generate a number of questions. It then becomes necessary to ask whether these questions can be answered through one study or if more than one study needed. 1 Additional research questions can be developed, but several basic principles should be taken into consideration. 1 All questions, primary and secondary, should be developed at the beginning and planning stages of a study. Any additional questions should never compromise the primary question because it is the primary research question that forms the basis of the hypothesis and study objectives. It must be kept in mind that within the scope of one study, the presence of a number of research questions will affect and potentially increase the complexity of both the study design and subsequent statistical analyses, not to mention the actual feasibility of answering every question. 1 A sensible strategy is to establish a single primary research question around which to focus the study plan. 3 In a study, the primary research question should be clearly stated at the end of the introduction of the grant proposal, and it usually specifies the population to be studied, the intervention to be implemented and other circumstantial factors. 4
Hulley and colleagues 2 have suggested the use of the FINER criteria in the development of a good research question ( Box 1 ). The FINER criteria highlight useful points that may increase the chances of developing a successful research project. A good research question should specify the population of interest, be of interest to the scientific community and potentially to the public, have clinical relevance and further current knowledge in the field (and of course be compliant with the standards of ethical boards and national research standards).
FINER criteria for a good research question
| Feasible | ||
| Interesting | ||
| Novel | ||
| Ethical | ||
| Relevant |
Adapted with permission from Wolters Kluwer Health. 2
Whereas the FINER criteria outline the important aspects of the question in general, a useful format to use in the development of a specific research question is the PICO format — consider the population (P) of interest, the intervention (I) being studied, the comparison (C) group (or to what is the intervention being compared) and the outcome of interest (O). 3 , 5 , 6 Often timing (T) is added to PICO ( Box 2 ) — that is, “Over what time frame will the study take place?” 1 The PICOT approach helps generate a question that aids in constructing the framework of the study and subsequently in protocol development by alluding to the inclusion and exclusion criteria and identifying the groups of patients to be included. Knowing the specific population of interest, intervention (and comparator) and outcome of interest may also help the researcher identify an appropriate outcome measurement tool. 7 The more defined the population of interest, and thus the more stringent the inclusion and exclusion criteria, the greater the effect on the interpretation and subsequent applicability and generalizability of the research findings. 1 , 2 A restricted study population (and exclusion criteria) may limit bias and increase the internal validity of the study; however, this approach will limit external validity of the study and, thus, the generalizability of the findings to the practical clinical setting. Conversely, a broadly defined study population and inclusion criteria may be representative of practical clinical practice but may increase bias and reduce the internal validity of the study.
PICOT criteria 1
| Population (patients) | ||
| Intervention (for intervention studies only) | ||
| Comparison group | ||
| Outcome of interest | ||
| Time |
A poorly devised research question may affect the choice of study design, potentially lead to futile situations and, thus, hamper the chance of determining anything of clinical significance, which will then affect the potential for publication. Without devoting appropriate resources to developing the research question, the quality of the study and subsequent results may be compromised. During the initial stages of any research study, it is therefore imperative to formulate a research question that is both clinically relevant and answerable.
Research hypothesis
The primary research question should be driven by the hypothesis rather than the data. 1 , 2 That is, the research question and hypothesis should be developed before the start of the study. This sounds intuitive; however, if we take, for example, a database of information, it is potentially possible to perform multiple statistical comparisons of groups within the database to find a statistically significant association. This could then lead one to work backward from the data and develop the “question.” This is counterintuitive to the process because the question is asked specifically to then find the answer, thus collecting data along the way (i.e., in a prospective manner). Multiple statistical testing of associations from data previously collected could potentially lead to spuriously positive findings of association through chance alone. 2 Therefore, a good hypothesis must be based on a good research question at the start of a trial and, indeed, drive data collection for the study.
The research or clinical hypothesis is developed from the research question and then the main elements of the study — sampling strategy, intervention (if applicable), comparison and outcome variables — are summarized in a form that establishes the basis for testing, statistical and ultimately clinical significance. 3 For example, in a research study comparing computer-assisted acetabular component insertion versus freehand acetabular component placement in patients in need of total hip arthroplasty, the experimental group would be computer-assisted insertion and the control/conventional group would be free-hand placement. The investigative team would first state a research hypothesis. This could be expressed as a single outcome (e.g., computer-assisted acetabular component placement leads to improved functional outcome) or potentially as a complex/composite outcome; that is, more than one outcome (e.g., computer-assisted acetabular component placement leads to both improved radiographic cup placement and improved functional outcome).
However, when formally testing statistical significance, the hypothesis should be stated as a “null” hypothesis. 2 The purpose of hypothesis testing is to make an inference about the population of interest on the basis of a random sample taken from that population. The null hypothesis for the preceding research hypothesis then would be that there is no difference in mean functional outcome between the computer-assisted insertion and free-hand placement techniques. After forming the null hypothesis, the researchers would form an alternate hypothesis stating the nature of the difference, if it should appear. The alternate hypothesis would be that there is a difference in mean functional outcome between these techniques. At the end of the study, the null hypothesis is then tested statistically. If the findings of the study are not statistically significant (i.e., there is no difference in functional outcome between the groups in a statistical sense), we cannot reject the null hypothesis, whereas if the findings were significant, we can reject the null hypothesis and accept the alternate hypothesis (i.e., there is a difference in mean functional outcome between the study groups), errors in testing notwithstanding. In other words, hypothesis testing confirms or refutes the statement that the observed findings did not occur by chance alone but rather occurred because there was a true difference in outcomes between these surgical procedures. The concept of statistical hypothesis testing is complex, and the details are beyond the scope of this article.
Another important concept inherent in hypothesis testing is whether the hypotheses will be 1-sided or 2-sided. A 2-sided hypothesis states that there is a difference between the experimental group and the control group, but it does not specify in advance the expected direction of the difference. For example, we asked whether there is there an improvement in outcomes with computer-assisted surgery or whether the outcomes worse with computer-assisted surgery. We presented a 2-sided test in the above example because we did not specify the direction of the difference. A 1-sided hypothesis states a specific direction (e.g., there is an improvement in outcomes with computer-assisted surgery). A 2-sided hypothesis should be used unless there is a good justification for using a 1-sided hypothesis. As Bland and Atlman 8 stated, “One-sided hypothesis testing should never be used as a device to make a conventionally nonsignificant difference significant.”
The research hypothesis should be stated at the beginning of the study to guide the objectives for research. Whereas the investigators may state the hypothesis as being 1-sided (there is an improvement with treatment), the study and investigators must adhere to the concept of clinical equipoise. According to this principle, a clinical (or surgical) trial is ethical only if the expert community is uncertain about the relative therapeutic merits of the experimental and control groups being evaluated. 9 It means there must exist an honest and professional disagreement among expert clinicians about the preferred treatment. 9
Designing a research hypothesis is supported by a good research question and will influence the type of research design for the study. Acting on the principles of appropriate hypothesis development, the study can then confidently proceed to the development of the research objective.
Research objective
The primary objective should be coupled with the hypothesis of the study. Study objectives define the specific aims of the study and should be clearly stated in the introduction of the research protocol. 7 From our previous example and using the investigative hypothesis that there is a difference in functional outcomes between computer-assisted acetabular component placement and free-hand placement, the primary objective can be stated as follows: this study will compare the functional outcomes of computer-assisted acetabular component insertion versus free-hand placement in patients undergoing total hip arthroplasty. Note that the study objective is an active statement about how the study is going to answer the specific research question. Objectives can (and often do) state exactly which outcome measures are going to be used within their statements. They are important because they not only help guide the development of the protocol and design of study but also play a role in sample size calculations and determining the power of the study. 7 These concepts will be discussed in other articles in this series.
From the surgeon’s point of view, it is important for the study objectives to be focused on outcomes that are important to patients and clinically relevant. For example, the most methodologically sound randomized controlled trial comparing 2 techniques of distal radial fixation would have little or no clinical impact if the primary objective was to determine the effect of treatment A as compared to treatment B on intraoperative fluoroscopy time. However, if the objective was to determine the effect of treatment A as compared to treatment B on patient functional outcome at 1 year, this would have a much more significant impact on clinical decision-making. Second, more meaningful surgeon–patient discussions could ensue, incorporating patient values and preferences with the results from this study. 6 , 7 It is the precise objective and what the investigator is trying to measure that is of clinical relevance in the practical setting.
The following is an example from the literature about the relation between the research question, hypothesis and study objectives:
Study: Warden SJ, Metcalf BR, Kiss ZS, et al. Low-intensity pulsed ultrasound for chronic patellar tendinopathy: a randomized, double-blind, placebo-controlled trial. Rheumatology 2008;47:467–71.
Research question: How does low-intensity pulsed ultrasound (LIPUS) compare with a placebo device in managing the symptoms of skeletally mature patients with patellar tendinopathy?
Research hypothesis: Pain levels are reduced in patients who receive daily active-LIPUS (treatment) for 12 weeks compared with individuals who receive inactive-LIPUS (placebo).
Objective: To investigate the clinical efficacy of LIPUS in the management of patellar tendinopathy symptoms.
The development of the research question is the most important aspect of a research project. A research project can fail if the objectives and hypothesis are poorly focused and underdeveloped. Useful tips for surgical researchers are provided in Box 3 . Designing and developing an appropriate and relevant research question, hypothesis and objectives can be a difficult task. The critical appraisal of the research question used in a study is vital to the application of the findings to clinical practice. Focusing resources, time and dedication to these 3 very important tasks will help to guide a successful research project, influence interpretation of the results and affect future publication efforts.
Tips for developing research questions, hypotheses and objectives for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Develop clear and well-defined primary and secondary (if needed) objectives.
- Ensure that the research question and objectives are answerable, feasible and clinically relevant.
FINER = feasible, interesting, novel, ethical, relevant; PICOT = population (patients), intervention (for intervention studies only), comparison group, outcome of interest, time.
Competing interests: No funding was received in preparation of this paper. Dr. Bhandari was funded, in part, by a Canada Research Chair, McMaster University.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Starting the research process
- Writing Strong Research Questions | Criteria & Examples
Writing Strong Research Questions | Criteria & Examples
Published on October 26, 2022 by Shona McCombes . Revised on November 21, 2023.
A research question pinpoints exactly what you want to find out in your work. A good research question is essential to guide your research paper , dissertation , or thesis .
All research questions should be:
- Focused on a single problem or issue
- Researchable using primary and/or secondary sources
- Feasible to answer within the timeframe and practical constraints
- Specific enough to answer thoroughly
- Complex enough to develop the answer over the space of a paper or thesis
- Relevant to your field of study and/or society more broadly

Table of contents
How to write a research question, what makes a strong research question, using sub-questions to strengthen your main research question, research questions quiz, other interesting articles, frequently asked questions about research questions.
You can follow these steps to develop a strong research question:
- Choose your topic
- Do some preliminary reading about the current state of the field
- Narrow your focus to a specific niche
- Identify the research problem that you will address
The way you frame your question depends on what your research aims to achieve. The table below shows some examples of how you might formulate questions for different purposes.
| Research question formulations | |
|---|---|
| Describing and exploring | |
| Explaining and testing | |
| Evaluating and acting | is X |
Using your research problem to develop your research question
| Example research problem | Example research question(s) |
|---|---|
| Teachers at the school do not have the skills to recognize or properly guide gifted children in the classroom. | What practical techniques can teachers use to better identify and guide gifted children? |
| Young people increasingly engage in the “gig economy,” rather than traditional full-time employment. However, it is unclear why they choose to do so. | What are the main factors influencing young people’s decisions to engage in the gig economy? |
Note that while most research questions can be answered with various types of research , the way you frame your question should help determine your choices.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Research questions anchor your whole project, so it’s important to spend some time refining them. The criteria below can help you evaluate the strength of your research question.
Focused and researchable
| Criteria | Explanation |
|---|---|
| Focused on a single topic | Your central research question should work together with your research problem to keep your work focused. If you have multiple questions, they should all clearly tie back to your central aim. |
| Answerable using | Your question must be answerable using and/or , or by reading scholarly sources on the to develop your argument. If such data is impossible to access, you likely need to rethink your question. |
| Not based on value judgements | Avoid subjective words like , , and . These do not give clear criteria for answering the question. |
Feasible and specific
| Criteria | Explanation |
|---|---|
| Answerable within practical constraints | Make sure you have enough time and resources to do all research required to answer your question. If it seems you will not be able to gain access to the data you need, consider narrowing down your question to be more specific. |
| Uses specific, well-defined concepts | All the terms you use in the research question should have clear meanings. Avoid vague language, jargon, and too-broad ideas. |
| Does not demand a conclusive solution, policy, or course of action | Research is about informing, not instructing. Even if your project is focused on a practical problem, it should aim to improve understanding rather than demand a ready-made solution. If ready-made solutions are necessary, consider conducting instead. Action research is a research method that aims to simultaneously investigate an issue as it is solved. In other words, as its name suggests, action research conducts research and takes action at the same time. |
Complex and arguable
| Criteria | Explanation |
|---|---|
| Cannot be answered with or | Closed-ended, / questions are too simple to work as good research questions—they don’t provide enough for robust investigation and discussion. |
| Cannot be answered with easily-found facts | If you can answer the question through a single Google search, book, or article, it is probably not complex enough. A good research question requires original data, synthesis of multiple sources, and original interpretation and argumentation prior to providing an answer. |
Relevant and original
| Criteria | Explanation |
|---|---|
| Addresses a relevant problem | Your research question should be developed based on initial reading around your . It should focus on addressing a problem or gap in the existing knowledge in your field or discipline. |
| Contributes to a timely social or academic debate | The question should aim to contribute to an existing and current debate in your field or in society at large. It should produce knowledge that future researchers or practitioners can later build on. |
| Has not already been answered | You don’t have to ask something that nobody has ever thought of before, but your question should have some aspect of originality. For example, you can focus on a specific location, or explore a new angle. |
Chances are that your main research question likely can’t be answered all at once. That’s why sub-questions are important: they allow you to answer your main question in a step-by-step manner.
Good sub-questions should be:
- Less complex than the main question
- Focused only on 1 type of research
- Presented in a logical order
Here are a few examples of descriptive and framing questions:
- Descriptive: According to current government arguments, how should a European bank tax be implemented?
- Descriptive: Which countries have a bank tax/levy on financial transactions?
- Framing: How should a bank tax/levy on financial transactions look at a European level?
Keep in mind that sub-questions are by no means mandatory. They should only be asked if you need the findings to answer your main question. If your main question is simple enough to stand on its own, it’s okay to skip the sub-question part. As a rule of thumb, the more complex your subject, the more sub-questions you’ll need.
Try to limit yourself to 4 or 5 sub-questions, maximum. If you feel you need more than this, it may be indication that your main research question is not sufficiently specific. In this case, it’s is better to revisit your problem statement and try to tighten your main question up.
Prevent plagiarism. Run a free check.
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
Methodology
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
The way you present your research problem in your introduction varies depending on the nature of your research paper . A research paper that presents a sustained argument will usually encapsulate this argument in a thesis statement .
A research paper designed to present the results of empirical research tends to present a research question that it seeks to answer. It may also include a hypothesis —a prediction that will be confirmed or disproved by your research.
As you cannot possibly read every source related to your topic, it’s important to evaluate sources to assess their relevance. Use preliminary evaluation to determine whether a source is worth examining in more depth.
This involves:
- Reading abstracts , prefaces, introductions , and conclusions
- Looking at the table of contents to determine the scope of the work
- Consulting the index for key terms or the names of important scholars
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (“ x affects y because …”).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses . In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.

Formulating a main research question can be a difficult task. Overall, your question should contribute to solving the problem that you have defined in your problem statement .
However, it should also fulfill criteria in three main areas:
- Researchability
- Feasibility and specificity
- Relevance and originality
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, November 21). Writing Strong Research Questions | Criteria & Examples. Scribbr. Retrieved August 21, 2024, from https://www.scribbr.com/research-process/research-questions/
Is this article helpful?

Shona McCombes
Other students also liked, how to define a research problem | ideas & examples, how to write a problem statement | guide & examples, 10 research question examples to guide your research project, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
IMAGES
COMMENTS
A statistical question is a question that seeks to collect data and provide insights about a population or a sample. It goes beyond simple factual responses and requires analysis and interpretation. Statistical questions cannot be answered with a simple "yes" or "no," but rather yield a range of possible answers.
When to perform a statistical test. You can perform statistical tests on data that have been collected in a statistically valid manner - either through an experiment, or through observations made using probability sampling methods.. For a statistical test to be valid, your sample size needs to be large enough to approximate the true distribution of the population being studied.
A research question should be specific and testable, like measuring the effect of coffee on cardiovascular health. Statistical analysis, utilizing concepts such as the null hypothesis, alternative hypothesis, confidence levels, and statistical power, provides a strong foundation for interpreting results and generalizing findings.
Five Examples of Statistical Research Questions. In writing the statistical research questions, I provide a topic that shows the variables of the study, the study description, and a link to the original scientific article to give you a glimpse of the real-world examples. Topic 1: Physical Fitness and Academic Achievement
Research Questions and Types of Statistical Studies. In a statistical study, a population is a set of all people or objects that share certain characteristics.A sample is a subset of the population used in the study.Subjects are the individuals or objects in the sample.Subjects are often people, but could be animals, plants, or things. Variables are the characteristics of the subjects we study.
A research question is 'a question that a research project sets out to answer'. Picking a research question is a crucial part of both quantitative and emotional research. To outline a research question , one should sort out what sort of study will be coordinated, for instance, an emotional, quantitative, or mixed audit.
Table of contents. Step 1: Write your hypotheses and plan your research design. Step 2: Collect data from a sample. Step 3: Summarise your data with descriptive statistics. Step 4: Test hypotheses or make estimates with inferential statistics.
The first question asks for a ready-made solution, and is not focused or researchable. The second question is a clearer comparative question, but note that it may not be practically feasible. For a smaller research project or thesis, it could be narrowed down further to focus on the effectiveness of drunk driving laws in just one or two countries.
Step 5: Present your findings. The results of hypothesis testing will be presented in the results and discussion sections of your research paper, dissertation or thesis.. In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p-value).
This article provides five essential tips to guide you in selecting the right statistical test for your research. 1. Understand Your Data. The foundation of any statistical analysis begins with a thorough understanding of the available data. First, it is important to recognize the types of data available. Categorical data, for example, includes ...
Jun 21, 2023. 1. Choosing the right statistical test is crucial for accurate data analysis and valid research conclusions. As a student of Data Science, I understand the challenges of navigating ...
The choice of statistical test used for analysis of data from a research study is crucial in interpreting the results of the study. This article gives an overview of the various factors that determine the selection of a statistical test and lists some statistical testsused in common practice. How to cite this article: Ranganathan P. An ...
Real-World Examples of Statistical Test Selection. Example 1: A/B Testing for Website Optimization. Example 2: Customer Satisfaction across Age Groups. Example 3: Examining the Relationship between Variables. Common Mistakes to Avoid When Choosing a Statistical Test. Mistake 1: Ignoring the data type.
The appropriate test is determined by the variables being compared. Some common statistical tests include t-tests, ANOVA and chi-square tests. T-tests compare whether there are differences in a quantitative variable between two values of a categorical variable. For example, a t-test could be useful to compare the length of stay for knee ...
Quantitative research is the process of collecting and analyzing numerical data to describe, predict, or control variables of interest. This type of research helps in testing the causal relationships between variables, making predictions, and generalizing results to wider populations. The purpose of quantitative research is to test a predefined ...
Descriptive statistics, although relatively simple, are a critically important part of any quantitative data analysis. Measures of central tendency include the mean (average), median and mode. Skewness indicates whether a dataset leans to one side or another. Measures of dispersion include the range, variance and standard deviation.
The correct statistical test for determining if there's an association between class level and number of parties attended each term is the (1)Chi-square test of independence. Explanation: To determine if there is an association between class level (freshman, sophomore, junior, senior) and the number of parties attended each term, we would use ...
Example: Inferential statistics. You randomly select a sample of 11th graders in your state and collect data on their SAT scores and other characteristics. You can use inferential statistics to make estimates and test hypotheses about the whole population of 11th graders in the state based on your sample data.
Research question. Interest in a particular topic usually begins the research process, but it is the familiarity with the subject that helps define an appropriate research question for a study. 1 Questions then arise out of a perceived knowledge deficit within a subject area or field of study. 2 Indeed, Haynes suggests that it is important to know "where the boundary between current ...
Final answer: The choice of research method and statistical test depends on the nature of the research question and the type of data being collected. For example, when examining the impact of regular exercise on stress levels among college students, a t-test could be used to compare the mean stress levels of students who exercise regularly with those who do not.
A good research question is essential to guide your research paper, dissertation, or thesis. All research questions should be: Focused on a single problem or issue. Researchable using primary and/or secondary sources. Feasible to answer within the timeframe and practical constraints. Specific enough to answer thoroughly.
The most appropriate statistical test to use when answering the research question "Is there a difference in systolic blood pressure at baseline and at four weeks for 7 participants randomly assigned to a placebo or new medication for BP?" is the t-test. Therefore, the correct answer is option B. t - Test.
Click here 👆 to get an answer to your question ️ what statistical test would you do ? explain why you chose this test See what teachers have to say about Brainly's new learning tools! ... Brainly App. Brainly Tutor. Find a math tutor. For students. For teachers. For parents. Honor code. Textbook Solutions. Log in Join for free. profile.