- Prompt Library
- DS/AI Trends
- Stats Tools
- Interview Questions
- Generative AI
- Machine Learning
- Deep Learning

Hypothesis Testing Steps & Examples

Table of Contents
What is a Hypothesis testing?
As per the definition from Oxford languages, a hypothesis is a supposition or proposed explanation made on the basis of limited evidence as a starting point for further investigation. As per the Dictionary page on Hypothesis , Hypothesis means a proposition or set of propositions, set forth as an explanation for the occurrence of some specified group of phenomena, either asserted merely as a provisional conjecture to guide investigation (working hypothesis) or accepted as highly probable in the light of established facts.
The hypothesis can be defined as the claim that can either be related to the truth about something that exists in the world, or, truth about something that’s needs to be established a fresh . In simple words, another word for the hypothesis is the “claim” . Until the claim is proven to be true, it is called the hypothesis. Once the claim is proved, it becomes the new truth or new knowledge about the thing. For example , let’s say that a claim is made that students studying for more than 6 hours a day gets more than 90% of marks in their examination. Now, this is just a claim or a hypothesis and not the truth in the real world. However, in order for the claim to become the truth for widespread adoption, it needs to be proved using pieces of evidence, e.g., data. In order to reject this claim or otherwise, one needs to do some empirical analysis by gathering data samples and evaluating the claim. The process of gathering data and evaluating the claims or hypotheses with the goal to reject or otherwise (failing to reject) can be called as hypothesis testing . Note the wordings – “failing to reject”. It means that we don’t have enough evidence to reject the claim. Thus, until the time that new evidence comes up, the claim can be considered the truth. There are different techniques to test the hypothesis in order to reach the conclusion of whether the hypothesis can be used to represent the truth of the world.
One must note that the hypothesis testing never constitutes a proof that the hypothesis is absolute truth based on the observations. It only provides added support to consider the hypothesis as truth until the time that new evidences can against the hypotheses can be gathered. We can never be 100% sure about truth related to those hypotheses based on the hypothesis testing.
Simply speaking, hypothesis testing is a framework that can be used to assert whether the claim or the hypothesis made about a real-world/real-life event can be seen as the truth or otherwise based on the given data (evidences).
Hypothesis Testing Examples
Before we get ahead and start understanding more details about hypothesis and hypothesis testing steps, lets take a look at some real-world examples of how to think about hypothesis and hypothesis testing when dealing with real-world problems :
- Customers are churning because they ain’t getting response to their complaints or issues
- Customers are churning because there are other competitive services in the market which are providing these services at lower cost.
- Customers are churning because there are other competitive services which are providing more services at the same cost.
- It is claimed that a 500 gm sugar packet for a particular brand, say XYZA, contains sugar of less than 500 gm, say around 480gm. Can this claim be taken as truth? How do we know that this claim is true? This is a hypothesis until proved.
- A group of doctors claims that quitting smoking increases lifespan. Can this claim be taken as new truth? The hypothesis is that quitting smoking results in an increase in lifespan.
- It is claimed that brisk walking for half an hour every day reverses diabetes. In order to accept this in your lifestyle, you may need evidence that supports this claim or hypothesis.
- It is claimed that doing Pranayama yoga for 30 minutes a day can help in easing stress by 50%. This can be termed as hypothesis and would require testing / validation for it to be established as a truth and recommended for widespread adoption.
- One common real-life example of hypothesis testing is election polling. In order to predict the outcome of an election, pollsters take a sample of the population and ask them who they plan to vote for. They then use hypothesis testing to assess whether their sample is representative of the population as a whole. If the results of the hypothesis test are significant, it means that the sample is representative and that the poll can be used to predict the outcome of the election. However, if the results are not significant, it means that the sample is not representative and that the poll should not be used to make predictions.
- Machine learning models make predictions based on the input data. Each of the machine learning model representing a function approximation can be taken as a hypothesis. All different models constitute what is called as hypothesis space .
- As part of a linear regression machine learning model , it is claimed that there is a relationship between the response variables and predictor variables? Can this hypothesis or claim be taken as truth? Let’s say, the hypothesis is that the housing price depends upon the average income of people already staying in the locality. How true is this hypothesis or claim? The relationship between response variable and each of the predictor variables can be evaluated using T-test and T-statistics .
- For linear regression model , one of the hypothesis is that there is no relationship between the response variable and any of the predictor variables. Thus, if b1, b2, b3 are three parameters, all of them is equal to 0. b1 = b2 = b3 = 0. This is where one performs F-test and use F-statistics to test this hypothesis.
You may note different hypotheses which are listed above. The next step would be validate some of these hypotheses. This is where data scientists will come into picture. One or more data scientists may be asked to work on different hypotheses. This would result in these data scientists looking for appropriate data related to the hypothesis they are working. This section will be detailed out in near future.
State the Hypothesis to begin Hypothesis Testing
The first step to hypothesis testing is defining or stating a hypothesis. Before the hypothesis can be tested, we need to formulate the hypothesis in terms of mathematical expressions. There are two important aspects to pay attention to, prior to the formulation of the hypothesis. The following represents different types of hypothesis that could be put to hypothesis testing:
- Claim made against the well-established fact : The case in which a fact is well-established, or accepted as truth or “knowledge” and a new claim is made about this well-established fact. For example , when you buy a packet of 500 gm of sugar, you assume that the packet does contain at the minimum 500 gm of sugar and not any less, based on the label of 500 gm on the packet. In this case, the fact is given or assumed to be the truth. A new claim can be made that the 500 gm sugar contains sugar weighing less than 500 gm. This claim needs to be tested before it is accepted as truth. Such cases could be considered for hypothesis testing if this is claimed that the assumption or the default state of being is not true. The claim to be established as new truth can be stated as “alternate hypothesis”. The opposite state can be stated as “null hypothesis”. Here the claim that the 500 gm packet consists of sugar less than 500 grams would be stated as alternate hypothesis. The opposite state which is the sugar packet consists 500 gm is null hypothesis.
- Claim to establish the new truth : The case in which there is some claim made about the reality that exists in the world (fact). For example , the fact that the housing price depends upon the average income of people already staying in the locality can be considered as a claim and not assumed to be true. Another example could be the claim that running 5 miles a day would result in a reduction of 10 kg of weight within a month. There could be varied such claims which when required to be proved as true have to go through hypothesis testing. The claim to be established as new truth can be stated as “alternate hypothesis”. The opposite state can be stated as “null hypothesis”. Running 5 miles a day would result in reduction of 10 kg within a month would be stated as alternate hypothesis.
Based on the above considerations, the following hypothesis can be stated for doing hypothesis testing.
- The packet of 500 gm of sugar contains sugar of weight less than 500 gm. (Claim made against the established fact). This is a new knowledge which requires hypothesis testing to get established and acted upon.
- The housing price depends upon the average income of the people staying in the locality. This is a new knowledge which requires hypothesis testing to get established and acted upon.
- Running 5 miles a day results in a reduction of 10 kg of weight within a month. This is a new knowledge which requires hypothesis testing to get established for widespread adoption.
Formulate Null & Alternate Hypothesis as Next Step
Once the hypothesis is defined or stated, the next step is to formulate the null and alternate hypothesis in order to begin hypothesis testing as described above.
What is a null hypothesis?
In the case where the given statement is a well-established fact or default state of being in the real world, one can call it a null hypothesis (in the simpler word, nothing new). Well-established facts don’t need any hypothesis testing and hence can be called the null hypothesis. In cases, when there are any new claims made which is not well established in the real world, the null hypothesis can be thought of as the default state or opposite state of that claim. For example , in the previous section, the claim or hypothesis is made that the students studying for more than 6 hours a day gets more than 90% of marks in their examination. The null hypothesis, in this case, will be that the claim is not true or real. The null hypothesis can be stated that there is no relationship or association between the students reading more than 6 hours a day and they getting 90% of the marks. Any occurrence is only a chance occurrence. Another example of hypothesis is when somebody is alleged that they have performed a crime.
Null hypothesis is denoted by letter H with 0, e.g., [latex]H_0[/latex]
What is an alternate hypothesis?
When the given statement is a claim (unexpected event in the real world) and not yet proven, one can call/formulate it as an alternate hypothesis and accordingly define a null hypothesis which is the opposite state of the hypothesis. The alternate hypothesis is a new knowledge or truth that needs to be established. In simple words, the hypothesis or claim that needs to be tested against reality in the real world can be termed the alternate hypothesis. In order to reach a conclusion that the claim (alternate hypothesis) can be considered the new knowledge or truth (based on the available evidence), it would be important to reject the null hypothesis. It should be noted that null and alternate hypotheses are mutually exclusive and at the same time asymmetric. In the example given in the previous section, the claim that the students studying for more than 6 hours get more than 90% of marks can be termed as the alternate hypothesis.
Alternate hypothesis is denoted with H subscript a, e.g., [latex]H_a[/latex]
Once the hypothesis is formulated as null([latex]H_0[/latex]) and alternate hypothesis ([latex]H_a[/latex]), there are two possible outcomes that can happen from hypothesis testing. These outcomes are the following:
- Reject the null hypothesis : There is enough evidence based on which one can reject the null hypothesis. Let’s understand this with the help of an example provided earlier in this section. The null hypothesis is that there is no relationship between the students studying more than 6 hours a day and getting more than 90% marks. In a sample of 30 students studying more than 6 hours a day, it was found that they scored 91% marks. Given that the null hypothesis is true, this kind of hypothesis testing result will be highly unlikely. This kind of result can’t happen by chance. That would mean that the claim can be taken as the new truth or new knowledge in the real world. One can go and take further samples of 30 students to perform some more testing to validate the hypothesis. If similar results show up with other tests, it can be said with very high confidence that there is enough evidence to reject the null hypothesis that there is no relationship between the students studying more than 6 hours a day and getting more than 90% marks. In such cases, one can go to accept the claim as new truth that the students studying more than 6 hours a day get more than 90% marks. The hypothesis can be considered the new truth until the time that new tests provide evidence against this claim.
- Fail to reject the null hypothesis : There is not enough evidence-based on which one can reject the null hypothesis (well-established fact or reality). Thus, one would fail to reject the null hypothesis. In a sample of 30 students studying more than 6 hours a day, the students were found to score 75%. Given that the null hypothesis is true, this kind of result is fairly likely or expected. With the given sample, one can’t reject the null hypothesis that there is no relationship between the students studying more than 6 hours a day and getting more than 90% marks.
Examples of formulating the null and alternate hypothesis
The following are some examples of the null and alternate hypothesis.
| The weight of the sugar packet is 500 gm. (A well-established fact) | |
| The weight of the sugar packet is 500 gm. |
| Running 5 miles a day result in the reduction of 10 kg of weight within a month. | |
| Running 5 miles a day results in the reduction of 10 kg of weight within a month. |
| The housing price depend upon the average income of people staying in the locality. | |
| The housing price depends upon the average income of people staying in the locality. |
Hypothesis Testing Steps
Here is the diagram which represents the workflow of Hypothesis Testing.

Figure 1. Hypothesis Testing Steps
Based on the above, the following are some of the steps to be taken when doing hypothesis testing:
- State the hypothesis : First and foremost, the hypothesis needs to be stated. The hypothesis could either be the statement that is assumed to be true or the claim which is made to be true.
- Formulate the hypothesis : This step requires one to identify the Null and Alternate hypotheses or in simple words, formulate the hypothesis. Take an example of the canned sauce weighing 500 gm as the Null Hypothesis.
- Set the criteria for a decision : Identify test statistics that could be used to assess the Null Hypothesis. The test statistics with the above example would be the average weight of the sugar packet, and t-statistics would be used to determine the P-value. For different kinds of problems, different kinds of statistics including Z-statistics, T-statistics, F-statistics, etc can be used.
- Identify the level of significance (alpha) : Before starting the hypothesis testing, one would be required to set the significance level (also called as alpha ) which represents the value for which a P-value less than or equal to alpha is considered statistically significant. Typical values of alpha are 0.1, 0.05, and 0.01. In case the P-value is evaluated as statistically significant, the null hypothesis is rejected. In case, the P-value is more than the alpha value, the null hypothesis is failed to be rejected.
- Compute the test statistics : Next step is to calculate the test statistics (z-test, t-test, f-test, etc) to determine the P-value. If the sample size is more than 30, it is recommended to use z-statistics. Otherwise, t-statistics could be used. In the current example where 20 packets of canned sauce is selected for hypothesis testing, t-statistics will be calculated for the mean value of 505 gm (sample mean). The t-statistics would then be calculated as the difference of 505 gm (sample mean) and the population means (500 gm) divided by the sample standard deviation divided by the square root of sample size (20).
- Calculate the P-value of the test statistics : Once the test statistics have been calculated, find the P-value using either of t-table or a z-table. P-value is the probability of obtaining a test statistic (t-score or z-score) equal to or more extreme than the result obtained from the sample data, given that the null hypothesis H0 is true.
- Compare P-value with the level of significance : The significance level is set as the allowable range within which if the value appears, one will be failed to reject the Null Hypothesis. This region is also called as Non-rejection region . The value of alpha is compared with the p-value. If the p-value is less than the significance level, the test is statistically significant and hence, the null hypothesis will be rejected.
P-Value: Key to Statistical Hypothesis Testing
Once you formulate the hypotheses, there is the need to test those hypotheses. Meaning, say that the null hypothesis is stated as the statement that housing price does not depend upon the average income of people staying in the locality, it would be required to be tested by taking samples of housing prices and, based on the test results, this Null hypothesis could either be rejected or failed to be rejected . In hypothesis testing, the following two are the outcomes:
- Reject the Null hypothesis
- Fail to Reject the Null hypothesis
Take the above example of the sugar packet weighing 500 gm. The Null hypothesis is set as the statement that the sugar packet weighs 500 gm. After taking a sample of 20 sugar packets and testing/taking its weight, it was found that the average weight of the sugar packets came to 495 gm. The test statistics (t-statistics) were calculated for this sample and the P-value was determined. Let’s say the P-value was found to be 15%. Assuming that the level of significance is selected to be 5%, the test statistic is not statistically significant (P-value > 5%) and thus, the null hypothesis fails to get rejected. Thus, one could safely conclude that the sugar packet does weigh 500 gm. However, if the average weight of canned sauce would have found to be 465 gm, this is way beyond/away from the mean value of 500 gm and one could have ended up rejecting the Null Hypothesis based on the P-value .
Hypothesis Testing for Problem Analysis & Solution Implementation
Hypothesis testing can be applied in both problem analysis and solution implementation. The following represents method on how you can apply hypothesis testing technique for both problem and solution space:
- Problem Analysis : Hypothesis testing is a systematic way to validate assumptions or educated guesses during problem analysis. It allows for a structured investigation into the nature of a problem and its potential root causes. In this process, a null hypothesis and an alternative hypothesis are usually defined. The null hypothesis generally asserts that no significant change or effect exists, while the alternative hypothesis posits the opposite. Through controlled experiments, data collection, or statistical analysis, these hypotheses are then tested to determine their validity. For example, if a software company notices a sudden increase in user churn rate, they might hypothesize that the recent update to their application is the root cause. The null hypothesis could be that the update has no effect on churn rate, while the alternative hypothesis would assert that the update significantly impacts the churn rate. By analyzing user behavior and feedback before and after the update, and perhaps running A/B tests where one user group has the update and another doesn’t, the company can test these hypotheses. If the alternative hypothesis is confirmed, the company can then focus on identifying specific issues in the update that may be causing the increased churn, thereby moving closer to a solution.
- Solution Implementation : Hypothesis testing can also be a valuable tool during the solution implementation phase, serving as a method to evaluate the effectiveness of proposed remedies. By setting up a specific hypothesis about the expected outcome of a solution, organizations can create targeted metrics and KPIs to measure success. For example, if a retail business is facing low customer retention rates, they might implement a loyalty program as a solution. The hypothesis could be that introducing a loyalty program will increase customer retention by at least 15% within six months. The null hypothesis would state that the loyalty program has no significant effect on retention rates. To test this, the company can compare retention metrics from before and after the program’s implementation, possibly even setting up control groups for more robust analysis. By applying statistical tests to this data, the company can determine whether their hypothesis is confirmed or refuted, thereby gauging the effectiveness of their solution and making data-driven decisions for future actions.
- Tests of Significance
- Hypothesis testing for the Mean
- z-statistics vs t-statistics (Khan Academy)
Hypothesis testing quiz
The claim that needs to be established is set as ____________, the outcome of hypothesis testing is _________.
Please select 2 correct answers
P-value is defined as the probability of obtaining the result as extreme given the null hypothesis is true
There is a claim that doing pranayama yoga results in reversing diabetes. which of the following is true about null hypothesis.
In this post, you learned about hypothesis testing and related nuances such as the null and alternate hypothesis formulation techniques, ways to go about doing hypothesis testing etc. In data science, one of the reasons why one needs to understand the concepts of hypothesis testing is the need to verify the relationship between the dependent (response) and independent (predictor) variables. One would, thus, need to understand the related concepts such as hypothesis formulation into null and alternate hypothesis, level of significance, test statistics calculation, P-value, etc. Given that the relationship between dependent and independent variables is a sort of hypothesis or claim , the null hypothesis could be set as the scenario where there is no relationship between dependent and independent variables.
Recent Posts

- ROC Curve & AUC Explained with Python Examples - August 28, 2024
- Accuracy, Precision, Recall & F1-Score – Python Examples - August 28, 2024
- Logistic Regression in Machine Learning: Python Example - August 26, 2024
Ajitesh Kumar
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
- Search for:
ChatGPT Prompts (250+)
- Generate Design Ideas for App
- Expand Feature Set of App
- Create a User Journey Map for App
- Generate Visual Design Ideas for App
- Generate a List of Competitors for App
- ROC Curve & AUC Explained with Python Examples
- Accuracy, Precision, Recall & F1-Score – Python Examples
- Logistic Regression in Machine Learning: Python Example
- Reducing Overfitting vs Models Complexity: Machine Learning
- Model Parallelism vs Data Parallelism: Examples
Data Science / AI Trends
- • Prepend any arxiv.org link with talk2 to load the paper into a responsive chat application
- • Custom LLM and AI Agents (RAG) On Structured + Unstructured Data - AI Brain For Your Organization
- • Guides, papers, lecture, notebooks and resources for prompt engineering
- • Common tricks to make LLMs efficient and stable
- • Machine learning in finance
Free Online Tools
- Create Scatter Plots Online for your Excel Data
- Histogram / Frequency Distribution Creation Tool
- Online Pie Chart Maker Tool
- Z-test vs T-test Decision Tool
- Independent samples t-test calculator
Recent Comments
I found it very helpful. However the differences are not too understandable for me
Very Nice Explaination. Thankyiu very much,
in your case E respresent Member or Oraganization which include on e or more peers?
Such a informative post. Keep it up
Thank you....for your support. you given a good solution for me.
- Comprehensive Learning Paths
- 150+ Hours of Videos
- Complete Access to Jupyter notebooks, Datasets, References.

Hypothesis Testing – A Deep Dive into Hypothesis Testing, The Backbone of Statistical Inference
- September 21, 2023
Explore the intricacies of hypothesis testing, a cornerstone of statistical analysis. Dive into methods, interpretations, and applications for making data-driven decisions.

In this Blog post we will learn:
- What is Hypothesis Testing?
- Steps in Hypothesis Testing 2.1. Set up Hypotheses: Null and Alternative 2.2. Choose a Significance Level (α) 2.3. Calculate a test statistic and P-Value 2.4. Make a Decision
- Example : Testing a new drug.
- Example in python
1. What is Hypothesis Testing?
In simple terms, hypothesis testing is a method used to make decisions or inferences about population parameters based on sample data. Imagine being handed a dice and asked if it’s biased. By rolling it a few times and analyzing the outcomes, you’d be engaging in the essence of hypothesis testing.
Think of hypothesis testing as the scientific method of the statistics world. Suppose you hear claims like “This new drug works wonders!” or “Our new website design boosts sales.” How do you know if these statements hold water? Enter hypothesis testing.
2. Steps in Hypothesis Testing
- Set up Hypotheses : Begin with a null hypothesis (H0) and an alternative hypothesis (Ha).
- Choose a Significance Level (α) : Typically 0.05, this is the probability of rejecting the null hypothesis when it’s actually true. Think of it as the chance of accusing an innocent person.
- Calculate Test statistic and P-Value : Gather evidence (data) and calculate a test statistic.
- p-value : This is the probability of observing the data, given that the null hypothesis is true. A small p-value (typically ≤ 0.05) suggests the data is inconsistent with the null hypothesis.
- Decision Rule : If the p-value is less than or equal to α, you reject the null hypothesis in favor of the alternative.
2.1. Set up Hypotheses: Null and Alternative
Before diving into testing, we must formulate hypotheses. The null hypothesis (H0) represents the default assumption, while the alternative hypothesis (H1) challenges it.
For instance, in drug testing, H0 : “The new drug is no better than the existing one,” H1 : “The new drug is superior .”
2.2. Choose a Significance Level (α)
When You collect and analyze data to test H0 and H1 hypotheses. Based on your analysis, you decide whether to reject the null hypothesis in favor of the alternative, or fail to reject / Accept the null hypothesis.
The significance level, often denoted by $α$, represents the probability of rejecting the null hypothesis when it is actually true.
In other words, it’s the risk you’re willing to take of making a Type I error (false positive).
Type I Error (False Positive) :
- Symbolized by the Greek letter alpha (α).
- Occurs when you incorrectly reject a true null hypothesis . In other words, you conclude that there is an effect or difference when, in reality, there isn’t.
- The probability of making a Type I error is denoted by the significance level of a test. Commonly, tests are conducted at the 0.05 significance level , which means there’s a 5% chance of making a Type I error .
- Commonly used significance levels are 0.01, 0.05, and 0.10, but the choice depends on the context of the study and the level of risk one is willing to accept.
Example : If a drug is not effective (truth), but a clinical trial incorrectly concludes that it is effective (based on the sample data), then a Type I error has occurred.
Type II Error (False Negative) :
- Symbolized by the Greek letter beta (β).
- Occurs when you accept a false null hypothesis . This means you conclude there is no effect or difference when, in reality, there is.
- The probability of making a Type II error is denoted by β. The power of a test (1 – β) represents the probability of correctly rejecting a false null hypothesis.
Example : If a drug is effective (truth), but a clinical trial incorrectly concludes that it is not effective (based on the sample data), then a Type II error has occurred.
Balancing the Errors :

In practice, there’s a trade-off between Type I and Type II errors. Reducing the risk of one typically increases the risk of the other. For example, if you want to decrease the probability of a Type I error (by setting a lower significance level), you might increase the probability of a Type II error unless you compensate by collecting more data or making other adjustments.
It’s essential to understand the consequences of both types of errors in any given context. In some situations, a Type I error might be more severe, while in others, a Type II error might be of greater concern. This understanding guides researchers in designing their experiments and choosing appropriate significance levels.
2.3. Calculate a test statistic and P-Value
Test statistic : A test statistic is a single number that helps us understand how far our sample data is from what we’d expect under a null hypothesis (a basic assumption we’re trying to test against). Generally, the larger the test statistic, the more evidence we have against our null hypothesis. It helps us decide whether the differences we observe in our data are due to random chance or if there’s an actual effect.
P-value : The P-value tells us how likely we would get our observed results (or something more extreme) if the null hypothesis were true. It’s a value between 0 and 1. – A smaller P-value (typically below 0.05) means that the observation is rare under the null hypothesis, so we might reject the null hypothesis. – A larger P-value suggests that what we observed could easily happen by random chance, so we might not reject the null hypothesis.
2.4. Make a Decision
Relationship between $α$ and P-Value
When conducting a hypothesis test:
We then calculate the p-value from our sample data and the test statistic.
Finally, we compare the p-value to our chosen $α$:
- If $p−value≤α$: We reject the null hypothesis in favor of the alternative hypothesis. The result is said to be statistically significant.
- If $p−value>α$: We fail to reject the null hypothesis. There isn’t enough statistical evidence to support the alternative hypothesis.
3. Example : Testing a new drug.
Imagine we are investigating whether a new drug is effective at treating headaches faster than drug B.
Setting Up the Experiment : You gather 100 people who suffer from headaches. Half of them (50 people) are given the new drug (let’s call this the ‘Drug Group’), and the other half are given a sugar pill, which doesn’t contain any medication.
- Set up Hypotheses : Before starting, you make a prediction:
- Null Hypothesis (H0): The new drug has no effect. Any difference in healing time between the two groups is just due to random chance.
- Alternative Hypothesis (H1): The new drug does have an effect. The difference in healing time between the two groups is significant and not just by chance.
Calculate Test statistic and P-Value : After the experiment, you analyze the data. The “test statistic” is a number that helps you understand the difference between the two groups in terms of standard units.
For instance, let’s say:
- The average healing time in the Drug Group is 2 hours.
- The average healing time in the Placebo Group is 3 hours.
The test statistic helps you understand how significant this 1-hour difference is. If the groups are large and the spread of healing times in each group is small, then this difference might be significant. But if there’s a huge variation in healing times, the 1-hour difference might not be so special.
Imagine the P-value as answering this question: “If the new drug had NO real effect, what’s the probability that I’d see a difference as extreme (or more extreme) as the one I found, just by random chance?”
For instance:
- P-value of 0.01 means there’s a 1% chance that the observed difference (or a more extreme difference) would occur if the drug had no effect. That’s pretty rare, so we might consider the drug effective.
- P-value of 0.5 means there’s a 50% chance you’d see this difference just by chance. That’s pretty high, so we might not be convinced the drug is doing much.
- If the P-value is less than ($α$) 0.05: the results are “statistically significant,” and they might reject the null hypothesis , believing the new drug has an effect.
- If the P-value is greater than ($α$) 0.05: the results are not statistically significant, and they don’t reject the null hypothesis , remaining unsure if the drug has a genuine effect.
4. Example in python
For simplicity, let’s say we’re using a t-test (common for comparing means). Let’s dive into Python:
Making a Decision : “The results are statistically significant! p-value < 0.05 , The drug seems to have an effect!” If not, we’d say, “Looks like the drug isn’t as miraculous as we thought.”
5. Conclusion
Hypothesis testing is an indispensable tool in data science, allowing us to make data-driven decisions with confidence. By understanding its principles, conducting tests properly, and considering real-world applications, you can harness the power of hypothesis testing to unlock valuable insights from your data.
More Articles
F statistic formula – explained, correlation – connecting the dots, the role of correlation in data analysis, sampling and sampling distributions – a comprehensive guide on sampling and sampling distributions, law of large numbers – a deep dive into the world of statistics, central limit theorem – a deep dive into central limit theorem and its significance in statistics, similar articles, complete introduction to linear regression in r, how to implement common statistical significance tests and find the p value, logistic regression – a complete tutorial with examples in r.
Subscribe to Machine Learning Plus for high value data science content
© Machinelearningplus. All rights reserved.

Machine Learning A-Z™: Hands-On Python & R In Data Science
Free sample videos:.


- Onsite training
3,000,000+ delegates
15,000+ clients
1,000+ locations
- KnowledgePass
- Log a ticket
01344203999 Available 24/7

Hypothesis Testing in Data Science: It's Usage and Types
Hypothesis Testing in Data Science is a crucial method for making informed decisions from data. This blog explores its essential usage in analysing trends and patterns, and the different types such as null, alternative, one-tailed, and two-tailed tests, providing a comprehensive understanding for both beginners and advanced practitioners.

Exclusive 40% OFF
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Share this Resource
- Advanced Data Science Certification
- Data Science and Blockchain Training
- Big Data Analysis
- Python Data Science Course
- Advanced Data Analytics Course

Table of Contents
1) What is Hypothesis Testing in Data Science?
2) Importance of Hypothesis Testing in Data Science
3) Types of Hypothesis Testing
4) Basic steps in Hypothesis Testing
5) Real-world use cases of Hypothesis Testing
6) Conclusion
What is Hypothesis Testing in Data Science?
Hypothesis Testing in Data Science is a statistical method used to assess the validity of assumptions or claims about a population based on sample data. It involves formulating two Hypotheses, the null Hypothesis (H0) and the alternative Hypothesis (Ha or H1), and then using statistical tests to find out if there is enough evidence to support the alternative Hypothesis.
Hypothetical Testing is a critical tool for making data-driven decisions, evaluating the significance of observed effects or differences, and drawing meaningful conclusions from data, allowing Data Scientists to uncover patterns, relationships, and insights that inform various domains, from medicine to business and beyond.
Unlock the power of data with our comprehensive Data Science & Analytics Training . Sign up now!
Importance of Hypothesis Testing in Data Science
The significance of Hypothesis Testing in Data Science cannot be overstated. It serves as the cornerstone of data-driven decision-making. By systematically testing Hypotheses, Data Scientists can:

Objective decision-making
Hypothesis Testing provides a structured and impartial method for making decisions based on data. In a world where biases can skew perceptions, Data Scientists rely on this method to ensure that their conclusions are grounded in empirical evidence, making their decisions more objective and trustworthy.
Statistical rigour
Data Scientists deal with large amounts of data, and Hypothesis Testing helps them make sense of it. It quantifies the significance of observed patterns, differences, or relationships. This statistical rigour is essential in distinguishing between mere coincidences and meaningful findings, reducing the likelihood of making decisions based on random chance.
Resource allocation
Resources, whether they are financial, human, or time-related, are often limited. Hypothesis Testing enables efficient resource allocation by guiding Data Scientists towards strategies or interventions that are statistically significant. This ensures that efforts are directed where they are most likely to yield valuable results.
Risk management
In domains like healthcare and finance, where lives and livelihoods are at stake, Hypothesis Testing is a critical tool for risk assessment. For instance, in drug development, Hypothesis Testing is used to determine the safety and efficiency of new treatments, helping mitigate potential risks to patients.
Innovation and progress
Hypothesis Testing fosters innovation by providing a systematic framework to evaluate new ideas, products, or strategies. It encourages a cycle of experimentation, feedback, and improvement, driving continuous progress and innovation.
Strategic decision-making
Organisations base their strategies on data-driven insights. Hypothesis Testing enables them to make informed decisions about market trends, customer behaviour, and product development. These decisions are grounded in empirical evidence, increasing the likelihood of success.
Scientific integrity
In scientific research, Hypothesis Testing is integral to maintaining the integrity of research findings. It ensures that conclusions are drawn from rigorous statistical analysis rather than conjecture. This is essential for advancing knowledge and building upon existing research.
Regulatory compliance
Many industries, such as pharmaceuticals and aviation, operate under strict regulatory frameworks. Hypothesis Testing is essential for demonstrating compliance with safety and quality standards. It provides the statistical evidence required to meet regulatory requirements.
Supercharge your data skills with our Big Data and Analytics Training – register now!
Types of Hypothesis Testing
Hypothesis Testing can be seen in several different types. In total, we have five types of Hypothesis Testing. They are described below as follows:

Alternative Hypothesis
The Alternative Hypothesis, denoted as Ha or H1, is the assertion or claim that researchers aim to support with their data analysis. It represents the opposite of the null Hypothesis (H0) and suggests that there is a significant effect, relationship, or difference in the population. In simpler terms, it's the statement that researchers hope to find evidence for during their analysis. For example, if you are testing a new drug's efficacy, the alternative Hypothesis might state that the drug has a measurable positive effect on patients' health.
Null Hypothesis
The Null Hypothesis, denoted as H0, is the default assumption in Hypothesis Testing. It posits that there is no significant effect, relationship, or difference in the population being studied. In other words, it represents the status quo or the absence of an effect. Researchers typically set out to challenge or disprove the Null Hypothesis by collecting and analysing data. Using the drug efficacy example again, the Null Hypothesis might state that the new drug has no effect on patients' health.
Non-directional Hypothesis
A Non-directional Hypothesis, also known as a two-tailed Hypothesis, is used when researchers are interested in whether there is any significant difference, effect, or relationship in either direction (positive or negative). This type of Hypothesis allows for the possibility of finding effects in both directions. For instance, in a study comparing the performance of two groups, a Non-directional Hypothesis would suggest that there is a significant difference between the groups, without specifying which group performs better.
Directional Hypothesis
A Directional Hypothesis, also called a one-tailed Hypothesis, is employed when researchers have a specific expectation about the direction of the effect, relationship, or difference they are investigating. In this case, the Hypothesis predicts an outcome in a particular direction—either positive or negative. For example, if you expect that a new teaching method will improve student test scores, a directional Hypothesis would state that the new method leads to higher test scores.
Statistical Hypothesis
A Statistical Hypothesis is a Hypothesis formulated in a way that it can be tested using statistical methods. It involves specific numerical values or parameters that can be measured or compared. Statistical Hypotheses are crucial for quantitative research and often involve means, proportions, variances, correlations, or other measurable quantities. These Hypotheses provide a precise framework for conducting statistical tests and drawing conclusions based on data analysis.
Want to unlock the power of Big Data Analysis? Join our Big Data Analysis Course today!
Basic steps in Hypothesis Testing
Hypothesis Testing is a systematic approach used in statistics to make informed decisions based on data. It is a critical tool in Data Science, research, and many other fields where data analysis is employed. The following are the basic steps involved in Hypothesis Testing:

1) Formulate Hypotheses
The first step in Hypothesis Testing is to clearly define your research question and translate it into two mutually exclusive Hypotheses:
a) Null Hypothesis (H0): This is the default assumption, often representing the status quo or the absence of an effect. It states that there is no significant difference, relationship, or effect in the population.
b) Alternative Hypothesis (Ha or H1): This is the statement that contradicts the null Hypothesis. It suggests that there is a significant difference, relationship, or effect in the population.
The formulation of these Hypotheses is crucial, as they serve as the foundation for your entire Hypothesis Testing process.
2) Collect data
With your Hypotheses in place, the next step is to gather relevant data through surveys, experiments, observations, or any other suitable method. The data collected should be representative of the population you are studying. The quality and quantity of data are essential factors in the success of your Hypothesis Testing.
3) Choose a significance level (α)
Before conducting the statistical test, you need to decide on the level of significance, denoted as α. The significance level represents the threshold for statistical significance and determines how confident you want to be in your results. A common choice is α = 0.05, which implies a 5% chance of making a Type I error (rejecting the null Hypothesis when it's true). You can choose a different α value based on the specific requirements of your analysis.
4) Perform the test
Based on the nature of your data and the Hypotheses you've formulated, select the appropriate statistical test. There are various tests available, including t-tests, chi-squared tests, ANOVA, regression analysis, and more. The chosen test should align with the type of data (e.g., continuous or categorical) and the research question (e.g., comparing means or testing for independence).
Execute the selected statistical test on your data to obtain test statistics and p-values. The test statistics quantify the difference or effect you are investigating, while the p-value represents the probability of obtaining the observed results if the null Hypothesis were true.
5) Analyse the results
Once you have the test statistics and p-value, it's time to interpret the results. The primary focus is on the p-value:
a) If the p-value is less than or equal to your chosen significance level (α), typically 0.05, you have evidence to reject the null Hypothesis. This shows that there is a significant difference, relationship, or effect in the population.
b) If the p-value is more than α, you fail to reject the null Hypothesis, showing that there is insufficient evidence to support the alternative Hypothesis.
6) Draw conclusions
Based on the analysis of the p-value and the comparison to the significance level, you can draw conclusions about your research question:
a) In case you reject the null Hypothesis, you can accept the alternative Hypothesis and make inferences based on the evidence provided by your data.
b) In case you fail to reject the null Hypothesis, you do not accept the alternative Hypothesis, and you acknowledge that there is no significant evidence to support your claim.
It's important to communicate your findings clearly, including the implications and limitations of your analysis.
Real-world use cases of Hypothesis Testing
The following are some of the real-world use cases of Hypothesis Testing.
a) Medical research: Hypothesis Testing is crucial in determining the efficacy of new medications or treatments. For instance, in a clinical trial, researchers use Hypothesis Testing to assess whether a new drug is significantly more effective than a placebo in treating a particular condition.
b) Marketing and advertising: Businesses employ Hypothesis Testing to evaluate the impact of marketing campaigns. A company may test whether a new advertising strategy leads to a significant increase in sales compared to the previous approach.
c) Manufacturing and quality control: Manufacturing industries use Hypothesis Testing to ensure product quality. For example, in the automotive industry, Hypothesis Testing can be applied to test whether a new manufacturing process results in a significant reduction in defects.
d) Education: In the field of education, Hypothesis Testing can be used to assess the effectiveness of teaching methods. Researchers may test whether a new teaching approach leads to statistically significant improvements in student performance.
e) Finance and investment: Investment strategies are often evaluated using Hypothesis Testing. Investors may test whether a new investment strategy outperforms a benchmark index over a specified period.

Conclusion
To sum it up, Hypothesis Testing in Data Science is a powerful tool that enables Data Scientists to make evidence-based decisions and draw meaningful conclusions from data. Understanding the types, methods, and steps involved in Hypothesis Testing is essential for any Data Scientist. By rigorously applying Hypothesis Testing techniques, you can gain valuable insights and drive informed decision-making in various domains.
Want to take your Data Science skills to the next level? Join our Big Data Analytics & Data Science Integration Course now!
Frequently Asked Questions
Upcoming data, analytics & ai resources batches & dates.
Fri 1st Nov 2024
Get A Quote
WHO WILL BE FUNDING THE COURSE?
My employer
By submitting your details you agree to be contacted in order to respond to your enquiry
- Business Analysis
- Lean Six Sigma Certification
Share this course
Our biggest summer sale.

We cannot process your enquiry without contacting you, please tick to confirm your consent to us for contacting you about your enquiry.
By submitting your details you agree to be contacted in order to respond to your enquiry.
We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Or select from our popular topics
- ITIL® Certification
- Scrum Certification
- ISO 9001 Certification
- Change Management Certification
- Microsoft Azure Certification
- Microsoft Excel Courses
- Explore more courses
Press esc to close
Fill out your contact details below and our training experts will be in touch.
Fill out your contact details below
Thank you for your enquiry!
One of our training experts will be in touch shortly to go over your training requirements.
Back to Course Information
Fill out your contact details below so we can get in touch with you regarding your training requirements.
* WHO WILL BE FUNDING THE COURSE?
Preferred Contact Method
No preference
Back to course information
Fill out your training details below
Fill out your training details below so we have a better idea of what your training requirements are.
HOW MANY DELEGATES NEED TRAINING?
HOW DO YOU WANT THE COURSE DELIVERED?
Online Instructor-led
Online Self-paced
WHEN WOULD YOU LIKE TO TAKE THIS COURSE?
Next 2 - 4 months
WHAT IS YOUR REASON FOR ENQUIRING?
Looking for some information
Looking for a discount
I want to book but have questions
One of our training experts will be in touch shortly to go overy your training requirements.
Your privacy & cookies!
Like many websites we use cookies. We care about your data and experience, so to give you the best possible experience using our site, we store a very limited amount of your data. Continuing to use this site or clicking “Accept & close” means that you agree to our use of cookies. Learn more about our privacy policy and cookie policy cookie policy .
We use cookies that are essential for our site to work. Please visit our cookie policy for more information. To accept all cookies click 'Accept & close'.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- How to Write a Strong Hypothesis | Guide & Examples
How to Write a Strong Hypothesis | Guide & Examples
Published on 6 May 2022 by Shona McCombes .
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations, and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more variables . An independent variable is something the researcher changes or controls. A dependent variable is something the researcher observes and measures.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Prevent plagiarism, run a free check.
Step 1: ask a question.
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2: Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalise more complex constructs.
Step 3: Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
Step 4: Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
Step 5: Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if … then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
Step 6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis. The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
| Research question | Hypothesis | Null hypothesis |
|---|---|---|
| What are the health benefits of eating an apple a day? | Increasing apple consumption in over-60s will result in decreasing frequency of doctor’s visits. | Increasing apple consumption in over-60s will have no effect on frequency of doctor’s visits. |
| Which airlines have the most delays? | Low-cost airlines are more likely to have delays than premium airlines. | Low-cost and premium airlines are equally likely to have delays. |
| Can flexible work arrangements improve job satisfaction? | Employees who have flexible working hours will report greater job satisfaction than employees who work fixed hours. | There is no relationship between working hour flexibility and job satisfaction. |
| How effective is secondary school sex education at reducing teen pregnancies? | Teenagers who received sex education lessons throughout secondary school will have lower rates of unplanned pregnancy than teenagers who did not receive any sex education. | Secondary school sex education has no effect on teen pregnancy rates. |
| What effect does daily use of social media have on the attention span of under-16s? | There is a negative correlation between time spent on social media and attention span in under-16s. | There is no relationship between social media use and attention span in under-16s. |
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis is not just a guess. It should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations, and statistical analysis of data).
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (‘ x affects y because …’).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses. In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2022, May 06). How to Write a Strong Hypothesis | Guide & Examples. Scribbr. Retrieved 29 August 2024, from https://www.scribbr.co.uk/research-methods/hypothesis-writing/
Is this article helpful?

Shona McCombes
Other students also liked, operationalisation | a guide with examples, pros & cons, what is a conceptual framework | tips & examples, a quick guide to experimental design | 5 steps & examples.
- The Open University
- Accessibility hub
- Guest user / Sign out
- Study with The Open University
My OpenLearn Profile
Personalise your OpenLearn profile, save your favourite content and get recognition for your learning
Data analysis: hypothesis testing

Course description
Course content, course reviews.
Making decisions about the world based on data requires a process that bridges the gap between unstructured data and the decision. Statistical hypothesis testing helps decision-making by formulating beliefs about the world, including people, organisations or other objects, and formally testing these beliefs.
In this free course, you will study the principles of hypothesis testing, including the specification of significance levels, as well as one-sided and two-sided tests. Finally, you will learn how to perform a hypothesis test of the mean of a variable, as well as the proportion of individuals in a dataset with a certain characteristic.
You will use spreadsheets throughout the course as the central tool used by professionals for simple data management and analysis.
This OpenLearn course is an adapted extract from the Open University course B126 Business data analytics and decision making .
Course learning outcomes
After studying this course, you should be able to:
- understand the principle of hypothesis testing
- understand the idea of alpha in hypothesis testing
- differentiate between one-tailed and two-tailed tests
- understand hypothesis testing of means and proportions
- report the exact p-value of a test.
First Published: 02/01/2024
Updated: 02/01/2024
Rate and Review
Rate this course, review this course.
Log into OpenLearn to leave reviews and join in the conversation.
Create an account to get more
Track your progress.
Review and track your learning through your OpenLearn Profile.
Statement of Participation
On completion of a course you will earn a Statement of Participation.
Access all course activities
Take course quizzes and access all learning.
Review the course
When you have finished a course leave a review and tell others what you think.
For further information, take a look at our frequently asked questions which may give you the support you need.
About this free course
Become an ou student, download this course, share this free course.
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Statistical Hypothesis Testing Overview
By Jim Frost 59 Comments
In this blog post, I explain why you need to use statistical hypothesis testing and help you navigate the essential terminology. Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables.
This post provides an overview of statistical hypothesis testing. If you need to perform hypothesis tests, consider getting my book, Hypothesis Testing: An Intuitive Guide .
Why You Should Perform Statistical Hypothesis Testing

Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. You gain tremendous benefits by working with a sample. In most cases, it is simply impossible to observe the entire population to understand its properties. The only alternative is to collect a random sample and then use statistics to analyze it.
While samples are much more practical and less expensive to work with, there are trade-offs. When you estimate the properties of a population from a sample, the sample statistics are unlikely to equal the actual population value exactly. For instance, your sample mean is unlikely to equal the population mean. The difference between the sample statistic and the population value is the sample error.
Differences that researchers observe in samples might be due to sampling error rather than representing a true effect at the population level. If sampling error causes the observed difference, the next time someone performs the same experiment the results might be different. Hypothesis testing incorporates estimates of the sampling error to help you make the correct decision. Learn more about Sampling Error .
For example, if you are studying the proportion of defects produced by two manufacturing methods, any difference you observe between the two sample proportions might be sample error rather than a true difference. If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics. That can be a costly mistake!
Let’s cover some basic hypothesis testing terms that you need to know.
Background information : Difference between Descriptive and Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
Hypothesis Testing
Hypothesis testing is a statistical analysis that uses sample data to assess two mutually exclusive theories about the properties of a population. Statisticians call these theories the null hypothesis and the alternative hypothesis. A hypothesis test assesses your sample statistic and factors in an estimate of the sample error to determine which hypothesis the data support.
When you can reject the null hypothesis, the results are statistically significant, and your data support the theory that an effect exists at the population level.
The effect is the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. For example, the mean difference between the health outcome for a treatment group and a control group is the effect.
Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size. Hypothesis tests convert your sample effect into a test statistic, which it evaluates for statistical significance. Learn more about Test Statistics .
An effect can be statistically significant, but that doesn’t necessarily indicate that it is important in a real-world, practical sense. For more information, read my post about Statistical vs. Practical Significance .
Null Hypothesis
The null hypothesis is one of two mutually exclusive theories about the properties of the population in hypothesis testing. Typically, the null hypothesis states that there is no effect (i.e., the effect size equals zero). The null is often signified by H 0 .
In all hypothesis testing, the researchers are testing an effect of some sort. The effect can be the effectiveness of a new vaccination, the durability of a new product, the proportion of defect in a manufacturing process, and so on. There is some benefit or difference that the researchers hope to identify.
However, it’s possible that there is no effect or no difference between the experimental groups. In statistics, we call this lack of an effect the null hypothesis. Therefore, if you can reject the null, you can favor the alternative hypothesis, which states that the effect exists (doesn’t equal zero) at the population level.
You can think of the null as the default theory that requires sufficiently strong evidence against in order to reject it.
For example, in a 2-sample t-test, the null often states that the difference between the two means equals zero.
When you can reject the null hypothesis, your results are statistically significant. Learn more about Statistical Significance: Definition & Meaning .
Related post : Understanding the Null Hypothesis in More Detail
Alternative Hypothesis
The alternative hypothesis is the other theory about the properties of the population in hypothesis testing. Typically, the alternative hypothesis states that a population parameter does not equal the null hypothesis value. In other words, there is a non-zero effect. If your sample contains sufficient evidence, you can reject the null and favor the alternative hypothesis. The alternative is often identified with H 1 or H A .
For example, in a 2-sample t-test, the alternative often states that the difference between the two means does not equal zero.
You can specify either a one- or two-tailed alternative hypothesis:
If you perform a two-tailed hypothesis test, the alternative states that the population parameter does not equal the null value. For example, when the alternative hypothesis is H A : μ ≠ 0, the test can detect differences both greater than and less than the null value.
A one-tailed alternative has more power to detect an effect but it can test for a difference in only one direction. For example, H A : μ > 0 can only test for differences that are greater than zero.
Related posts : Understanding T-tests and One-Tailed and Two-Tailed Hypothesis Tests Explained

P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null. You use P-values in conjunction with the significance level to determine whether your data favor the null or alternative hypothesis.
Related post : Interpreting P-values Correctly
Significance Level (Alpha)

For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
Use p-values and significance levels together to help you determine which hypothesis the data support. If the p-value is less than your significance level, you can reject the null and conclude that the effect is statistically significant. In other words, the evidence in your sample is strong enough to be able to reject the null hypothesis at the population level.
Related posts : Graphical Approach to Significance Levels and P-values and Conceptual Approach to Understanding Significance Levels
Types of Errors in Hypothesis Testing
Statistical hypothesis tests are not 100% accurate because they use a random sample to draw conclusions about entire populations. There are two types of errors related to drawing an incorrect conclusion.
- False positives: You reject a null that is true. Statisticians call this a Type I error . The Type I error rate equals your significance level or alpha (α).
- False negatives: You fail to reject a null that is false. Statisticians call this a Type II error. Generally, you do not know the Type II error rate. However, it is a larger risk when you have a small sample size , noisy data, or a small effect size. The type II error rate is also known as beta (β).
Statistical power is the probability that a hypothesis test correctly infers that a sample effect exists in the population. In other words, the test correctly rejects a false null hypothesis. Consequently, power is inversely related to a Type II error. Power = 1 – β. Learn more about Power in Statistics .
Related posts : Types of Errors in Hypothesis Testing and Estimating a Good Sample Size for Your Study Using Power Analysis
Which Type of Hypothesis Test is Right for You?
There are many different types of procedures you can use. The correct choice depends on your research goals and the data you collect. Do you need to understand the mean or the differences between means? Or, perhaps you need to assess proportions. You can even use hypothesis testing to determine whether the relationships between variables are statistically significant.
To choose the proper statistical procedure, you’ll need to assess your study objectives and collect the correct type of data . This background research is necessary before you begin a study.
Related Post : Hypothesis Tests for Continuous, Binary, and Count Data
Statistical tests are crucial when you want to use sample data to make conclusions about a population because these tests account for sample error. Using significance levels and p-values to determine when to reject the null hypothesis improves the probability that you will draw the correct conclusion.
To see an alternative approach to these traditional hypothesis testing methods, learn about bootstrapping in statistics !
If you want to see examples of hypothesis testing in action, I recommend the following posts that I have written:
- How Effective Are Flu Shots? This example shows how you can use statistics to test proportions.
- Fatality Rates in Star Trek . This example shows how to use hypothesis testing with categorical data.
- Busting Myths About the Battle of the Sexes . A fun example based on a Mythbusters episode that assess continuous data using several different tests.
- Are Yawns Contagious? Another fun example inspired by a Mythbusters episode.
Share this:

Reader Interactions

January 14, 2024 at 8:43 am
Hello professor Jim, how are you doing! Pls. What are the properties of a population and their examples? Thanks for your time and understanding.

January 14, 2024 at 12:57 pm
Please read my post about Populations vs. Samples for more information and examples.
Also, please note there is a search bar in the upper-right margin of my website. Use that to search for topics.

July 5, 2023 at 7:05 am
Hello, I have a question as I read your post. You say in p-values section
“P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null.”
But according to your definition of effect, the null states that an effect does not exist, correct? So what I assume you want to say is that “P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is **incorrect**.”
July 6, 2023 at 5:18 am
Hi Shrinivas,
The correct definition of p-value is that it is a probability that exists in the context of a true null hypothesis. So, the quotation is correct in stating “if the null hypothesis is correct.”
Essentially, the p-value tells you the likelihood of your observed results (or more extreme) if the null hypothesis is true. It gives you an idea of whether your results are surprising or unusual if there is no effect.
Hence, with sufficiently low p-values, you reject the null hypothesis because it’s telling you that your sample results were unlikely to have occurred if there was no effect in the population.
I hope that helps make it more clear. If not, let me know I’ll attempt to clarify!

May 8, 2023 at 12:47 am
Thanks a lot Ny best regards
May 7, 2023 at 11:15 pm
Hi Jim Can you tell me something about size effect? Thanks
May 8, 2023 at 12:29 am
Here’s a post that I’ve written about Effect Sizes that will hopefully tell you what you need to know. Please read that. Then, if you have any more specific questions about effect sizes, please post them there. Thanks!

January 7, 2023 at 4:19 pm
Hi Jim, I have only read two pages so far but I am really amazed because in few paragraphs you made me clearly understand the concepts of months of courses I received in biostatistics! Thanks so much for this work you have done it helps a lot!
January 10, 2023 at 3:25 pm
Thanks so much!

June 17, 2021 at 1:45 pm
Can you help in the following question: Rocinante36 is priced at ₹7 lakh and has been designed to deliver a mileage of 22 km/litre and a top speed of 140 km/hr. Formulate the null and alternative hypotheses for mileage and top speed to check whether the new models are performing as per the desired design specifications.

April 19, 2021 at 1:51 pm
Its indeed great to read your work statistics.
I have a doubt regarding the one sample t-test. So as per your book on hypothesis testing with reference to page no 45, you have mentioned the difference between “the sample mean and the hypothesised mean is statistically significant”. So as per my understanding it should be quoted like “the difference between the population mean and the hypothesised mean is statistically significant”. The catch here is the hypothesised mean represents the sample mean.
Please help me understand this.
Regards Rajat
April 19, 2021 at 3:46 pm
Thanks for buying my book. I’m so glad it’s been helpful!
The test is performed on the sample but the results apply to the population. Hence, if the difference between the sample mean (observed in your study) and the hypothesized mean is statistically significant, that suggests that population does not equal the hypothesized mean.
For one sample tests, the hypothesized mean is not the sample mean. It is a mean that you want to use for the test value. It usually represents a value that is important to your research. In other words, it’s a value that you pick for some theoretical/practical reasons. You pick it because you want to determine whether the population mean is different from that particular value.
I hope that helps!

November 5, 2020 at 6:24 am
Jim, you are such a magnificent statistician/economist/econometrician/data scientist etc whatever profession. Your work inspires and simplifies the lives of so many researchers around the world. I truly admire you and your work. I will buy a copy of each book you have on statistics or econometrics. Keep doing the good work. Remain ever blessed
November 6, 2020 at 9:47 pm
Hi Renatus,
Thanks so much for you very kind comments. You made my day!! I’m so glad that my website has been helpful. And, thanks so much for supporting my books! 🙂

November 2, 2020 at 9:32 pm
Hi Jim, I hope you are aware of 2019 American Statistical Association’s official statement on Statistical Significance: https://www.tandfonline.com/doi/full/10.1080/00031305.2019.1583913 In case you do not bother reading the full article, may I quote you the core message here: “We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way."
With best wishes,
November 3, 2020 at 2:09 am
I’m definitely aware of the debate surrounding how to use p-values most effectively. However, I need to correct you on one point. The link you provide is NOT a statement by the American Statistical Association. It is an editorial by several authors.
There is considerable debate over this issue. There are problems with p-values. However, as the authors state themselves, much of the problem is over people’s mindsets about how to use p-values and their incorrect interpretations about what statistical significance does and does not mean.
If you were to read my website more thoroughly, you’d be aware that I share many of their concerns and I address them in multiple posts. One of the authors’ key points is the need to be thoughtful and conduct thoughtful research and analysis. I emphasize this aspect in multiple posts on this topic. I’ll ask you to read the following three because they all address some of the authors’ concerns and suggestions. But you might run across others to read as well.
Five Tips for Using P-values to Avoid Being Misled How to Interpret P-values Correctly P-values and the Reproducibility of Experimental Results

September 24, 2020 at 11:52 pm
HI Jim, i just want you to know that you made explanation for Statistics so simple! I should say lesser and fewer words that reduce the complexity. All the best! 🙂
September 25, 2020 at 1:03 am
Thanks, Rene! Your kind words mean a lot to me! I’m so glad it has been helpful!

September 23, 2020 at 2:21 am
Honestly, I never understood stats during my entire M.Ed course and was another nightmare for me. But how easily you have explained each concept, I have understood stats way beyond my imagination. Thank you so much for helping ignorant research scholars like us. Looking forward to get hardcopy of your book. Kindly tell is it available through flipkart?
September 24, 2020 at 11:14 pm
I’m so happy to hear that my website has been helpful!
I checked on flipkart and it appears like my books are not available there. I’m never exactly sure where they’re available due to the vagaries of different distribution channels. They are available on Amazon in India.
Introduction to Statistics: An Intuitive Guide (Amazon IN) Hypothesis Testing: An Intuitive Guide (Amazon IN)

July 26, 2020 at 11:57 am
Dear Jim I am a teacher from India . I don’t have any background in statistics, and still I should tell that in a single read I can follow your explanations . I take my entire biostatistics class for botany graduates with your explanations. Thanks a lot. May I know how I can avail your books in India
July 28, 2020 at 12:31 am
Right now my books are only available as ebooks from my website. However, soon I’ll have some exciting news about other ways to obtain it. Stay tuned! I’ll announce it on my email list. If you’re not already on it, you can sign up using the form that is in the right margin of my website.

June 22, 2020 at 2:02 pm
Also can you please let me if this book covers topics like EDA and principal component analysis?
June 22, 2020 at 2:07 pm
This book doesn’t cover principal components analysis. Although, I wouldn’t really classify that as a hypothesis test. In the future, I might write a multivariate analysis book that would cover this and others. But, that’s well down the road.
My Introduction to Statistics covers EDA. That’s the largely graphical look at your data that you often do prior to hypothesis testing. The Introduction book perfectly leads right into the Hypothesis Testing book.
June 22, 2020 at 1:45 pm
Thanks for the detailed explanation. It does clear my doubts. I saw that your book related to hypothesis testing has the topics that I am studying currently. I am looking forward to purchasing it.
Regards, Take Care
June 19, 2020 at 1:03 pm
For this particular article I did not understand a couple of statements and it would great if you could help: 1)”If sample error causes the observed difference, the next time someone performs the same experiment the results might be different.” 2)”If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics.”
I discovered your articles by chance and now I keep coming back to read & understand statistical concepts. These articles are very informative & easy to digest. Thanks for the simplifying things.
June 20, 2020 at 9:53 pm
I’m so happy to hear that you’ve found my website to be helpful!
To answer your questions, keep in mind that a central tenant of inferential statistics is that the random sample that a study drew was only one of an infinite number of possible it could’ve drawn. Each random sample produces different results. Most results will cluster around the population value assuming they used good methodology. However, random sampling error always exists and makes it so that population estimates from a sample almost never exactly equal the correct population value.
So, imagine that we’re studying a medication and comparing the treatment and control groups. Suppose that the medicine is truly not effect and that the population difference between the treatment and control group is zero (i.e., no difference.) Despite the true difference being zero, most sample estimates will show some degree of either a positive or negative effect thanks to random sampling error. So, just because a study has an observed difference does not mean that a difference exists at the population level. So, on to your questions:
1. If the observed difference is just random error, then it makes sense that if you collected another random sample, the difference could change. It could change from negative to positive, positive to negative, more extreme, less extreme, etc. However, if the difference exists at the population level, most random samples drawn from the population will reflect that difference. If the medicine has an effect, most random samples will reflect that fact and not bounce around on both sides of zero as much.
2. This is closely related to the previous answer. If there is no difference at the population level, but say you approve the medicine because of the observed effects in a sample. Even though your random sample showed an effect (which was really random error), that effect doesn’t exist. So, when you start using it on a larger scale, people won’t benefit from the medicine. That’s why it’s important to separate out what is easily explained by random error versus what is not easily explained by it.
I think reading my post about how hypothesis tests work will help clarify this process. Also, in about 24 hours (as I write this), I’ll be releasing my new ebook about Hypothesis Testing!

May 29, 2020 at 5:23 am
Hi Jim, I really enjoy your blog. Can you please link me on your blog where you discuss about Subgroup analysis and how it is done? I need to use non parametric and parametric statistical methods for my work and also do subgroup analysis in order to identify potential groups of patients that may benefit more from using a treatment than other groups.
May 29, 2020 at 2:12 pm
Hi, I don’t have a specific article about subgroup analysis. However, subgroup analysis is just the dividing up of a larger sample into subgroups and then analyzing those subgroups separately. You can use the various analyses I write about on the subgroups.
Alternatively, you can include the subgroups in regression analysis as an indicator variable and include that variable as a main effect and an interaction effect to see how the relationships vary by subgroup without needing to subdivide your data. I write about that approach in my article about comparing regression lines . This approach is my preferred approach when possible.

April 19, 2020 at 7:58 am
sir is confidence interval is a part of estimation?

April 17, 2020 at 3:36 pm
Sir can u plz briefly explain alternatives of hypothesis testing? I m unable to find the answer
April 18, 2020 at 1:22 am
Assuming you want to draw conclusions about populations by using samples (i.e., inferential statistics ), you can use confidence intervals and bootstrap methods as alternatives to the traditional hypothesis testing methods.

March 9, 2020 at 10:01 pm
Hi JIm, could you please help with activities that can best teach concepts of hypothesis testing through simulation, Also, do you have any question set that would enhance students intuition why learning hypothesis testing as a topic in introductory statistics. Thanks.

March 5, 2020 at 3:48 pm
Hi Jim, I’m studying multiple hypothesis testing & was wondering if you had any material that would be relevant. I’m more trying to understand how testing multiple samples simultaneously affects your results & more on the Bonferroni Correction
March 5, 2020 at 4:05 pm
I write about multiple comparisons (aka post hoc tests) in the ANOVA context . I don’t talk about Bonferroni Corrections specifically but I cover related types of corrections. I’m not sure if that exactly addresses what you want to know but is probably the closest I have already written. I hope it helps!

January 14, 2020 at 9:03 pm
Thank you! Have a great day/evening.
January 13, 2020 at 7:10 pm
Any help would be greatly appreciated. What is the difference between The Hypothesis Test and The Statistical Test of Hypothesis?
January 14, 2020 at 11:02 am
They sound like the same thing to me. Unless this is specialized terminology for a particular field or the author was intending something specific, I’d guess they’re one and the same.

April 1, 2019 at 10:00 am
so these are the only two forms of Hypothesis used in statistical testing?
April 1, 2019 at 10:02 am
Are you referring to the null and alternative hypothesis? If so, yes, that’s those are the standard hypotheses in a statistical hypothesis test.
April 1, 2019 at 9:57 am
year very insightful post, thanks for the write up

October 27, 2018 at 11:09 pm
hi there, am upcoming statistician, out of all blogs that i have read, i have found this one more useful as long as my problem is concerned. thanks so much
October 27, 2018 at 11:14 pm
Hi Stano, you’re very welcome! Thanks for your kind words. They mean a lot! I’m happy to hear that my posts were able to help you. I’m sure you will be a fantastic statistician. Best of luck with your studies!

October 26, 2018 at 11:39 am
Dear Jim, thank you very much for your explanations! I have a question. Can I use t-test to compare two samples in case each of them have right bias?
October 26, 2018 at 12:00 pm
Hi Tetyana,
You’re very welcome!
The term “right bias” is not a standard term. Do you by chance mean right skewed distributions? In other words, if you plot the distribution for each group on a histogram they have longer right tails? These are not the symmetrical bell-shape curves of the normal distribution.
If that’s the case, yes you can as long as you exceed a specific sample size within each group. I include a table that contains these sample size requirements in my post about nonparametric vs parametric analyses .
Bias in statistics refers to cases where an estimate of a value is systematically higher or lower than the true value. If this is the case, you might be able to use t-tests, but you’d need to be sure to understand the nature of the bias so you would understand what the results are really indicating.
I hope this helps!

April 2, 2018 at 7:28 am
Simple and upto the point 👍 Thank you so much.
April 2, 2018 at 11:11 am
Hi Kalpana, thanks! And I’m glad it was helpful!

March 26, 2018 at 8:41 am
Am I correct if I say: Alpha – Probability of wrongly rejection of null hypothesis P-value – Probability of wrongly acceptance of null hypothesis
March 28, 2018 at 3:14 pm
You’re correct about alpha. Alpha is the probability of rejecting the null hypothesis when the null is true.
Unfortunately, your definition of the p-value is a bit off. The p-value has a fairly convoluted definition. It is the probability of obtaining the effect observed in a sample, or more extreme, if the null hypothesis is true. The p-value does NOT indicate the probability that either the null or alternative is true or false. Although, those are very common misinterpretations. To learn more, read my post about how to interpret p-values correctly .

March 2, 2018 at 6:10 pm
I recently started reading your blog and it is very helpful to understand each concept of statistical tests in easy way with some good examples. Also, I recommend to other people go through all these blogs which you posted. Specially for those people who have not statistical background and they are facing to many problems while studying statistical analysis.
Thank you for your such good blogs.
March 3, 2018 at 10:12 pm
Hi Amit, I’m so glad that my blog posts have been helpful for you! It means a lot to me that you took the time to write such a nice comment! Also, thanks for recommending by blog to others! I try really hard to write posts about statistics that are easy to understand.

January 17, 2018 at 7:03 am
I recently started reading your blog and I find it very interesting. I am learning statistics by my own, and I generally do many google search to understand the concepts. So this blog is quite helpful for me, as it have most of the content which I am looking for.
January 17, 2018 at 3:56 pm
Hi Shashank, thank you! And, I’m very glad to hear that my blog is helpful!

January 2, 2018 at 2:28 pm
thank u very much sir.
January 2, 2018 at 2:36 pm
You’re very welcome, Hiral!

November 21, 2017 at 12:43 pm
Thank u so much sir….your posts always helps me to be a #statistician
November 21, 2017 at 2:40 pm
Hi Sachin, you’re very welcome! I’m happy that you find my posts to be helpful!

November 19, 2017 at 8:22 pm
great post as usual, but it would be nice to see an example.
November 19, 2017 at 8:27 pm
Thank you! At the end of this post, I have links to four other posts that show examples of hypothesis tests in action. You’ll find what you’re looking for in those posts!
Comments and Questions Cancel reply
A Step-by-Step Guide to the Data Analysis Process
Like any scientific discipline, data analysis follows a rigorous step-by-step process. Each stage requires different skills and know-how. To get meaningful insights, though, it’s important to understand the process as a whole. An underlying framework is invaluable for producing results that stand up to scrutiny.
In this post, we’ll explore the main steps in the data analysis process. This will cover how to define your goal, collect data, and carry out an analysis. Where applicable, we’ll also use examples and highlight a few tools to make the journey easier. When you’re done, you’ll have a much better understanding of the basics. This will help you tweak the process to fit your own needs.
Here are the steps we’ll take you through:
- Defining the question
- Collecting the data
- Cleaning the data
- Analyzing the data
- Sharing your results
- Embracing failure
On popular request, we’ve also developed a video based on this article. Scroll further along this article to watch that.
Ready? Let’s get started with step one.
1. Step one: Defining the question
The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the ‘problem statement’.
Defining your objective means coming up with a hypothesis and figuring how to test it. Start by asking: What business problem am I trying to solve? While this might sound straightforward, it can be trickier than it seems. For instance, your organization’s senior management might pose an issue, such as: “Why are we losing customers?” It’s possible, though, that this doesn’t get to the core of the problem. A data analyst’s job is to understand the business and its goals in enough depth that they can frame the problem the right way.
Let’s say you work for a fictional company called TopNotch Learning. TopNotch creates custom training software for its clients. While it is excellent at securing new clients, it has much lower repeat business. As such, your question might not be, “Why are we losing customers?” but, “Which factors are negatively impacting the customer experience?” or better yet: “How can we boost customer retention while minimizing costs?”
Now you’ve defined a problem, you need to determine which sources of data will best help you solve it. This is where your business acumen comes in again. For instance, perhaps you’ve noticed that the sales process for new clients is very slick, but that the production team is inefficient. Knowing this, you could hypothesize that the sales process wins lots of new clients, but the subsequent customer experience is lacking. Could this be why customers don’t come back? Which sources of data will help you answer this question?
Tools to help define your objective
Defining your objective is mostly about soft skills, business knowledge, and lateral thinking. But you’ll also need to keep track of business metrics and key performance indicators (KPIs). Monthly reports can allow you to track problem points in the business. Some KPI dashboards come with a fee, like Databox and DashThis . However, you’ll also find open-source software like Grafana , Freeboard , and Dashbuilder . These are great for producing simple dashboards, both at the beginning and the end of the data analysis process.
2. Step two: Collecting the data
Once you’ve established your objective, you’ll need to create a strategy for collecting and aggregating the appropriate data. A key part of this is determining which data you need. This might be quantitative (numeric) data, e.g. sales figures, or qualitative (descriptive) data, such as customer reviews. All data fit into one of three categories: first-party, second-party, and third-party data. Let’s explore each one.
What is first-party data?
First-party data are data that you, or your company, have directly collected from customers. It might come in the form of transactional tracking data or information from your company’s customer relationship management (CRM) system. Whatever its source, first-party data is usually structured and organized in a clear, defined way. Other sources of first-party data might include customer satisfaction surveys, focus groups, interviews, or direct observation.
What is second-party data?
To enrich your analysis, you might want to secure a secondary data source. Second-party data is the first-party data of other organizations. This might be available directly from the company or through a private marketplace. The main benefit of second-party data is that they are usually structured, and although they will be less relevant than first-party data, they also tend to be quite reliable. Examples of second-party data include website, app or social media activity, like online purchase histories, or shipping data.
What is third-party data?
Third-party data is data that has been collected and aggregated from numerous sources by a third-party organization. Often (though not always) third-party data contains a vast amount of unstructured data points (big data). Many organizations collect big data to create industry reports or to conduct market research. The research and advisory firm Gartner is a good real-world example of an organization that collects big data and sells it on to other companies. Open data repositories and government portals are also sources of third-party data .
Tools to help you collect data
Once you’ve devised a data strategy (i.e. you’ve identified which data you need, and how best to go about collecting them) there are many tools you can use to help you. One thing you’ll need, regardless of industry or area of expertise, is a data management platform (DMP). A DMP is a piece of software that allows you to identify and aggregate data from numerous sources, before manipulating them, segmenting them, and so on. There are many DMPs available. Some well-known enterprise DMPs include Salesforce DMP , SAS , and the data integration platform, Xplenty . If you want to play around, you can also try some open-source platforms like Pimcore or D:Swarm .
Want to learn more about what data analytics is and the process a data analyst follows? We cover this topic (and more) in our free introductory short course for beginners. Check out tutorial one: An introduction to data analytics .
3. Step three: Cleaning the data
Once you’ve collected your data, the next step is to get it ready for analysis. This means cleaning, or ‘scrubbing’ it, and is crucial in making sure that you’re working with high-quality data . Key data cleaning tasks include:
- Removing major errors, duplicates, and outliers —all of which are inevitable problems when aggregating data from numerous sources.
- Removing unwanted data points —extracting irrelevant observations that have no bearing on your intended analysis.
- Bringing structure to your data —general ‘housekeeping’, i.e. fixing typos or layout issues, which will help you map and manipulate your data more easily.
- Filling in major gaps —as you’re tidying up, you might notice that important data are missing. Once you’ve identified gaps, you can go about filling them.
A good data analyst will spend around 70-90% of their time cleaning their data. This might sound excessive. But focusing on the wrong data points (or analyzing erroneous data) will severely impact your results. It might even send you back to square one…so don’t rush it! You’ll find a step-by-step guide to data cleaning here . You may be interested in this introductory tutorial to data cleaning, hosted by Dr. Humera Noor Minhas.
Carrying out an exploratory analysis
Another thing many data analysts do (alongside cleaning data) is to carry out an exploratory analysis. This helps identify initial trends and characteristics, and can even refine your hypothesis. Let’s use our fictional learning company as an example again. Carrying out an exploratory analysis, perhaps you notice a correlation between how much TopNotch Learning’s clients pay and how quickly they move on to new suppliers. This might suggest that a low-quality customer experience (the assumption in your initial hypothesis) is actually less of an issue than cost. You might, therefore, take this into account.
Tools to help you clean your data
Cleaning datasets manually—especially large ones—can be daunting. Luckily, there are many tools available to streamline the process. Open-source tools, such as OpenRefine , are excellent for basic data cleaning, as well as high-level exploration. However, free tools offer limited functionality for very large datasets. Python libraries (e.g. Pandas) and some R packages are better suited for heavy data scrubbing. You will, of course, need to be familiar with the languages. Alternatively, enterprise tools are also available. For example, Data Ladder , which is one of the highest-rated data-matching tools in the industry. There are many more. Why not see which free data cleaning tools you can find to play around with?
4. Step four: Analyzing the data
Finally, you’ve cleaned your data. Now comes the fun bit—analyzing it! The type of data analysis you carry out largely depends on what your goal is. But there are many techniques available. Univariate or bivariate analysis, time-series analysis, and regression analysis are just a few you might have heard of. More important than the different types, though, is how you apply them. This depends on what insights you’re hoping to gain. Broadly speaking, all types of data analysis fit into one of the following four categories.
Descriptive analysis
Descriptive analysis identifies what has already happened . It is a common first step that companies carry out before proceeding with deeper explorations. As an example, let’s refer back to our fictional learning provider once more. TopNotch Learning might use descriptive analytics to analyze course completion rates for their customers. Or they might identify how many users access their products during a particular period. Perhaps they’ll use it to measure sales figures over the last five years. While the company might not draw firm conclusions from any of these insights, summarizing and describing the data will help them to determine how to proceed.
Learn more: What is descriptive analytics?
Diagnostic analysis
Diagnostic analytics focuses on understanding why something has happened . It is literally the diagnosis of a problem, just as a doctor uses a patient’s symptoms to diagnose a disease. Remember TopNotch Learning’s business problem? ‘Which factors are negatively impacting the customer experience?’ A diagnostic analysis would help answer this. For instance, it could help the company draw correlations between the issue (struggling to gain repeat business) and factors that might be causing it (e.g. project costs, speed of delivery, customer sector, etc.) Let’s imagine that, using diagnostic analytics, TopNotch realizes its clients in the retail sector are departing at a faster rate than other clients. This might suggest that they’re losing customers because they lack expertise in this sector. And that’s a useful insight!
Predictive analysis
Predictive analysis allows you to identify future trends based on historical data . In business, predictive analysis is commonly used to forecast future growth, for example. But it doesn’t stop there. Predictive analysis has grown increasingly sophisticated in recent years. The speedy evolution of machine learning allows organizations to make surprisingly accurate forecasts. Take the insurance industry. Insurance providers commonly use past data to predict which customer groups are more likely to get into accidents. As a result, they’ll hike up customer insurance premiums for those groups. Likewise, the retail industry often uses transaction data to predict where future trends lie, or to determine seasonal buying habits to inform their strategies. These are just a few simple examples, but the untapped potential of predictive analysis is pretty compelling.
Prescriptive analysis
Prescriptive analysis allows you to make recommendations for the future. This is the final step in the analytics part of the process. It’s also the most complex. This is because it incorporates aspects of all the other analyses we’ve described. A great example of prescriptive analytics is the algorithms that guide Google’s self-driving cars. Every second, these algorithms make countless decisions based on past and present data, ensuring a smooth, safe ride. Prescriptive analytics also helps companies decide on new products or areas of business to invest in.
Learn more: What are the different types of data analysis?
5. Step five: Sharing your results
You’ve finished carrying out your analyses. You have your insights. The final step of the data analytics process is to share these insights with the wider world (or at least with your organization’s stakeholders!) This is more complex than simply sharing the raw results of your work—it involves interpreting the outcomes, and presenting them in a manner that’s digestible for all types of audiences. Since you’ll often present information to decision-makers, it’s very important that the insights you present are 100% clear and unambiguous. For this reason, data analysts commonly use reports, dashboards, and interactive visualizations to support their findings.
How you interpret and present results will often influence the direction of a business. Depending on what you share, your organization might decide to restructure, to launch a high-risk product, or even to close an entire division. That’s why it’s very important to provide all the evidence that you’ve gathered, and not to cherry-pick data. Ensuring that you cover everything in a clear, concise way will prove that your conclusions are scientifically sound and based on the facts. On the flip side, it’s important to highlight any gaps in the data or to flag any insights that might be open to interpretation. Honest communication is the most important part of the process. It will help the business, while also helping you to excel at your job!
Tools for interpreting and sharing your findings
There are tons of data visualization tools available, suited to different experience levels. Popular tools requiring little or no coding skills include Google Charts , Tableau , Datawrapper , and Infogram . If you’re familiar with Python and R, there are also many data visualization libraries and packages available. For instance, check out the Python libraries Plotly , Seaborn , and Matplotlib . Whichever data visualization tools you use, make sure you polish up your presentation skills, too. Remember: Visualization is great, but communication is key!
You can learn more about storytelling with data in this free, hands-on tutorial . We show you how to craft a compelling narrative for a real dataset, resulting in a presentation to share with key stakeholders. This is an excellent insight into what it’s really like to work as a data analyst!
6. Step six: Embrace your failures
The last ‘step’ in the data analytics process is to embrace your failures. The path we’ve described above is more of an iterative process than a one-way street. Data analytics is inherently messy, and the process you follow will be different for every project. For instance, while cleaning data, you might spot patterns that spark a whole new set of questions. This could send you back to step one (to redefine your objective). Equally, an exploratory analysis might highlight a set of data points you’d never considered using before. Or maybe you find that the results of your core analyses are misleading or erroneous. This might be caused by mistakes in the data, or human error earlier in the process.
While these pitfalls can feel like failures, don’t be disheartened if they happen. Data analysis is inherently chaotic, and mistakes occur. What’s important is to hone your ability to spot and rectify errors. If data analytics was straightforward, it might be easier, but it certainly wouldn’t be as interesting. Use the steps we’ve outlined as a framework, stay open-minded, and be creative. If you lose your way, you can refer back to the process to keep yourself on track.
In this post, we’ve covered the main steps of the data analytics process. These core steps can be amended, re-ordered and re-used as you deem fit, but they underpin every data analyst’s work:
- Define the question —What business problem are you trying to solve? Frame it as a question to help you focus on finding a clear answer.
- Collect data —Create a strategy for collecting data. Which data sources are most likely to help you solve your business problem?
- Clean the data —Explore, scrub, tidy, de-dupe, and structure your data as needed. Do whatever you have to! But don’t rush…take your time!
- Analyze the data —Carry out various analyses to obtain insights. Focus on the four types of data analysis: descriptive, diagnostic, predictive, and prescriptive.
- Share your results —How best can you share your insights and recommendations? A combination of visualization tools and communication is key.
- Embrace your mistakes —Mistakes happen. Learn from them. This is what transforms a good data analyst into a great one.
What next? From here, we strongly encourage you to explore the topic on your own. Get creative with the steps in the data analysis process, and see what tools you can find. As long as you stick to the core principles we’ve described, you can create a tailored technique that works for you.
To learn more, check out our free, 5-day data analytics short course . You might also be interested in the following:
- These are the top 9 data analytics tools
- 10 great places to find free datasets for your next project
- How to build a data analytics portfolio

How to Write a Hypothesis: A Step-by-Step Guide

Introduction
An overview of the research hypothesis, different types of hypotheses, variables in a hypothesis, how to formulate an effective research hypothesis, designing a study around your hypothesis.
The scientific method can derive and test predictions as hypotheses. Empirical research can then provide support (or lack thereof) for the hypotheses. Even failure to find support for a hypothesis still represents a valuable contribution to scientific knowledge. Let's look more closely at the idea of the hypothesis and the role it plays in research.

As much as the term exists in everyday language, there is a detailed development that informs the word "hypothesis" when applied to research. A good research hypothesis is informed by prior research and guides research design and data analysis , so it is important to understand how a hypothesis is defined and understood by researchers.
What is the simple definition of a hypothesis?
A hypothesis is a testable prediction about an outcome between two or more variables . It functions as a navigational tool in the research process, directing what you aim to predict and how.
What is the hypothesis for in research?
In research, a hypothesis serves as the cornerstone for your empirical study. It not only lays out what you aim to investigate but also provides a structured approach for your data collection and analysis.
Essentially, it bridges the gap between the theoretical and the empirical, guiding your investigation throughout its course.

What is an example of a hypothesis?
If you are studying the relationship between physical exercise and mental health, a suitable hypothesis could be: "Regular physical exercise leads to improved mental well-being among adults."
This statement constitutes a specific and testable hypothesis that directly relates to the variables you are investigating.
What makes a good hypothesis?
A good hypothesis possesses several key characteristics. Firstly, it must be testable, allowing you to analyze data through empirical means, such as observation or experimentation, to assess if there is significant support for the hypothesis. Secondly, a hypothesis should be specific and unambiguous, giving a clear understanding of the expected relationship between variables. Lastly, it should be grounded in existing research or theoretical frameworks , ensuring its relevance and applicability.
Understanding the types of hypotheses can greatly enhance how you construct and work with hypotheses. While all hypotheses serve the essential function of guiding your study, there are varying purposes among the types of hypotheses. In addition, all hypotheses stand in contrast to the null hypothesis, or the assumption that there is no significant relationship between the variables .
Here, we explore various kinds of hypotheses to provide you with the tools needed to craft effective hypotheses for your specific research needs. Bear in mind that many of these hypothesis types may overlap with one another, and the specific type that is typically used will likely depend on the area of research and methodology you are following.
Null hypothesis
The null hypothesis is a statement that there is no effect or relationship between the variables being studied. In statistical terms, it serves as the default assumption that any observed differences are due to random chance.
For example, if you're studying the effect of a drug on blood pressure, the null hypothesis might state that the drug has no effect.
Alternative hypothesis
Contrary to the null hypothesis, the alternative hypothesis suggests that there is a significant relationship or effect between variables.
Using the drug example, the alternative hypothesis would posit that the drug does indeed affect blood pressure. This is what researchers aim to prove.

Simple hypothesis
A simple hypothesis makes a prediction about the relationship between two variables, and only two variables.
For example, "Increased study time results in better exam scores." Here, "study time" and "exam scores" are the only variables involved.
Complex hypothesis
A complex hypothesis, as the name suggests, involves more than two variables. For instance, "Increased study time and access to resources result in better exam scores." Here, "study time," "access to resources," and "exam scores" are all variables.
This hypothesis refers to multiple potential mediating variables. Other hypotheses could also include predictions about variables that moderate the relationship between the independent variable and dependent variable .
Directional hypothesis
A directional hypothesis specifies the direction of the expected relationship between variables. For example, "Eating more fruits and vegetables leads to a decrease in heart disease."
Here, the direction of heart disease is explicitly predicted to decrease, due to effects from eating more fruits and vegetables. All hypotheses typically specify the expected direction of the relationship between the independent and dependent variable, such that researchers can test if this prediction holds in their data analysis .

Statistical hypothesis
A statistical hypothesis is one that is testable through statistical methods, providing a numerical value that can be analyzed. This is commonly seen in quantitative research .
For example, "There is a statistically significant difference in test scores between students who study for one hour and those who study for two."
Empirical hypothesis
An empirical hypothesis is derived from observations and is tested through empirical methods, often through experimentation or survey data . Empirical hypotheses may also be assessed with statistical analyses.
For example, "Regular exercise is correlated with a lower incidence of depression," could be tested through surveys that measure exercise frequency and depression levels.
Causal hypothesis
A causal hypothesis proposes that one variable causes a change in another. This type of hypothesis is often tested through controlled experiments.
For example, "Smoking causes lung cancer," assumes a direct causal relationship.
Associative hypothesis
Unlike causal hypotheses, associative hypotheses suggest a relationship between variables but do not imply causation.
For instance, "People who smoke are more likely to get lung cancer," notes an association but doesn't claim that smoking causes lung cancer directly.
Relational hypothesis
A relational hypothesis explores the relationship between two or more variables but doesn't specify the nature of the relationship.
For example, "There is a relationship between diet and heart health," leaves the nature of the relationship (causal, associative, etc.) open to interpretation.
Logical hypothesis
A logical hypothesis is based on sound reasoning and logical principles. It's often used in theoretical research to explore abstract concepts, rather than being based on empirical data.
For example, "If all men are mortal and Socrates is a man, then Socrates is mortal," employs logical reasoning to make its point.

Let ATLAS.ti take you from research question to key insights
Get started with a free trial and see how ATLAS.ti can make the most of your data.
In any research hypothesis, variables play a critical role. These are the elements or factors that the researcher manipulates, controls, or measures. Understanding variables is essential for crafting a clear, testable hypothesis and for the stages of research that follow, such as data collection and analysis.
In the realm of hypotheses, there are generally two types of variables to consider: independent and dependent. Independent variables are what you, as the researcher, manipulate or change in your study. It's considered the cause in the relationship you're investigating. For instance, in a study examining the impact of sleep duration on academic performance, the independent variable would be the amount of sleep participants get.
Conversely, the dependent variable is the outcome you measure to gauge the effect of your manipulation. It's the effect in the cause-and-effect relationship. The dependent variable thus refers to the main outcome of interest in your study. In the same sleep study example, the academic performance, perhaps measured by exam scores or GPA, would be the dependent variable.
Beyond these two primary types, you might also encounter control variables. These are variables that could potentially influence the outcome and are therefore kept constant to isolate the relationship between the independent and dependent variables . For example, in the sleep and academic performance study, control variables could include age, diet, or even the subject of study.
By clearly identifying and understanding the roles of these variables in your hypothesis, you set the stage for a methodologically sound research project. It helps you develop focused research questions, design appropriate experiments or observations, and carry out meaningful data analysis . It's a step that lays the groundwork for the success of your entire study.

Crafting a strong, testable hypothesis is crucial for the success of any research project. It sets the stage for everything from your study design to data collection and analysis . Below are some key considerations to keep in mind when formulating your hypothesis:
- Be specific : A vague hypothesis can lead to ambiguous results and interpretations . Clearly define your variables and the expected relationship between them.
- Ensure testability : A good hypothesis should be testable through empirical means, whether by observation , experimentation, or other forms of data analysis.
- Ground in literature : Before creating your hypothesis, consult existing research and theories. This not only helps you identify gaps in current knowledge but also gives you valuable context and credibility for crafting your hypothesis.
- Use simple language : While your hypothesis should be conceptually sound, it doesn't have to be complicated. Aim for clarity and simplicity in your wording.
- State direction, if applicable : If your hypothesis involves a directional outcome (e.g., "increase" or "decrease"), make sure to specify this. You also need to think about how you will measure whether or not the outcome moved in the direction you predicted.
- Keep it focused : One of the common pitfalls in hypothesis formulation is trying to answer too many questions at once. Keep your hypothesis focused on a specific issue or relationship.
- Account for control variables : Identify any variables that could potentially impact the outcome and consider how you will control for them in your study.
- Be ethical : Make sure your hypothesis and the methods for testing it comply with ethical standards , particularly if your research involves human or animal subjects.

Designing your study involves multiple key phases that help ensure the rigor and validity of your research. Here we discuss these crucial components in more detail.
Literature review
Starting with a comprehensive literature review is essential. This step allows you to understand the existing body of knowledge related to your hypothesis and helps you identify gaps that your research could fill. Your research should aim to contribute some novel understanding to existing literature, and your hypotheses can reflect this. A literature review also provides valuable insights into how similar research projects were executed, thereby helping you fine-tune your own approach.

Research methods
Choosing the right research methods is critical. Whether it's a survey, an experiment, or observational study, the methodology should be the most appropriate for testing your hypothesis. Your choice of methods will also depend on whether your research is quantitative, qualitative, or mixed-methods. Make sure the chosen methods align well with the variables you are studying and the type of data you need.
Preliminary research
Before diving into a full-scale study, it’s often beneficial to conduct preliminary research or a pilot study . This allows you to test your research methods on a smaller scale, refine your tools, and identify any potential issues. For instance, a pilot survey can help you determine if your questions are clear and if the survey effectively captures the data you need. This step can save you both time and resources in the long run.
Data analysis
Finally, planning your data analysis in advance is crucial for a successful study. Decide which statistical or analytical tools are most suited for your data type and research questions . For quantitative research, you might opt for t-tests, ANOVA, or regression analyses. For qualitative research , thematic analysis or grounded theory may be more appropriate. This phase is integral for interpreting your results and drawing meaningful conclusions in relation to your research question.

Turn data into evidence for insights with ATLAS.ti
Powerful analysis for your research paper or presentation is at your fingertips starting with a free trial.

- Business Essentials
- Leadership & Management
- Credential of Leadership, Impact, and Management in Business (CLIMB)
- Entrepreneurship & Innovation
- Digital Transformation
- Finance & Accounting
- Business in Society
- For Organizations
- Support Portal
- Media Coverage
- Founding Donors
- Leadership Team

- Harvard Business School →
- HBS Online →
- Business Insights →
Business Insights
Harvard Business School Online's Business Insights Blog provides the career insights you need to achieve your goals and gain confidence in your business skills.
- Career Development
- Communication
- Decision-Making
- Earning Your MBA
- Negotiation
- News & Events
- Productivity
- Staff Spotlight
- Student Profiles
- Work-Life Balance
- AI Essentials for Business
- Alternative Investments
- Business Analytics
- Business Strategy
- Business and Climate Change
- Creating Brand Value
- Design Thinking and Innovation
- Digital Marketing Strategy
- Disruptive Strategy
- Economics for Managers
- Entrepreneurship Essentials
- Financial Accounting
- Global Business
- Launching Tech Ventures
- Leadership Principles
- Leadership, Ethics, and Corporate Accountability
- Leading Change and Organizational Renewal
- Leading with Finance
- Management Essentials
- Negotiation Mastery
- Organizational Leadership
- Power and Influence for Positive Impact
- Strategy Execution
- Sustainable Business Strategy
- Sustainable Investing
- Winning with Digital Platforms
A Beginner’s Guide to Hypothesis Testing in Business

- 30 Mar 2021
Becoming a more data-driven decision-maker can bring several benefits to your organization, enabling you to identify new opportunities to pursue and threats to abate. Rather than allowing subjective thinking to guide your business strategy, backing your decisions with data can empower your company to become more innovative and, ultimately, profitable.
If you’re new to data-driven decision-making, you might be wondering how data translates into business strategy. The answer lies in generating a hypothesis and verifying or rejecting it based on what various forms of data tell you.
Below is a look at hypothesis testing and the role it plays in helping businesses become more data-driven.
Access your free e-book today.
What Is Hypothesis Testing?
To understand what hypothesis testing is, it’s important first to understand what a hypothesis is.
A hypothesis or hypothesis statement seeks to explain why something has happened, or what might happen, under certain conditions. It can also be used to understand how different variables relate to each other. Hypotheses are often written as if-then statements; for example, “If this happens, then this will happen.”
Hypothesis testing , then, is a statistical means of testing an assumption stated in a hypothesis. While the specific methodology leveraged depends on the nature of the hypothesis and data available, hypothesis testing typically uses sample data to extrapolate insights about a larger population.
Hypothesis Testing in Business
When it comes to data-driven decision-making, there’s a certain amount of risk that can mislead a professional. This could be due to flawed thinking or observations, incomplete or inaccurate data , or the presence of unknown variables. The danger in this is that, if major strategic decisions are made based on flawed insights, it can lead to wasted resources, missed opportunities, and catastrophic outcomes.
The real value of hypothesis testing in business is that it allows professionals to test their theories and assumptions before putting them into action. This essentially allows an organization to verify its analysis is correct before committing resources to implement a broader strategy.
As one example, consider a company that wishes to launch a new marketing campaign to revitalize sales during a slow period. Doing so could be an incredibly expensive endeavor, depending on the campaign’s size and complexity. The company, therefore, may wish to test the campaign on a smaller scale to understand how it will perform.
In this example, the hypothesis that’s being tested would fall along the lines of: “If the company launches a new marketing campaign, then it will translate into an increase in sales.” It may even be possible to quantify how much of a lift in sales the company expects to see from the effort. Pending the results of the pilot campaign, the business would then know whether it makes sense to roll it out more broadly.
Related: 9 Fundamental Data Science Skills for Business Professionals
Key Considerations for Hypothesis Testing
1. alternative hypothesis and null hypothesis.
In hypothesis testing, the hypothesis that’s being tested is known as the alternative hypothesis . Often, it’s expressed as a correlation or statistical relationship between variables. The null hypothesis , on the other hand, is a statement that’s meant to show there’s no statistical relationship between the variables being tested. It’s typically the exact opposite of whatever is stated in the alternative hypothesis.
For example, consider a company’s leadership team that historically and reliably sees $12 million in monthly revenue. They want to understand if reducing the price of their services will attract more customers and, in turn, increase revenue.
In this case, the alternative hypothesis may take the form of a statement such as: “If we reduce the price of our flagship service by five percent, then we’ll see an increase in sales and realize revenues greater than $12 million in the next month.”
The null hypothesis, on the other hand, would indicate that revenues wouldn’t increase from the base of $12 million, or might even decrease.
Check out the video below about the difference between an alternative and a null hypothesis, and subscribe to our YouTube channel for more explainer content.
2. Significance Level and P-Value
Statistically speaking, if you were to run the same scenario 100 times, you’d likely receive somewhat different results each time. If you were to plot these results in a distribution plot, you’d see the most likely outcome is at the tallest point in the graph, with less likely outcomes falling to the right and left of that point.

With this in mind, imagine you’ve completed your hypothesis test and have your results, which indicate there may be a correlation between the variables you were testing. To understand your results' significance, you’ll need to identify a p-value for the test, which helps note how confident you are in the test results.
In statistics, the p-value depicts the probability that, assuming the null hypothesis is correct, you might still observe results that are at least as extreme as the results of your hypothesis test. The smaller the p-value, the more likely the alternative hypothesis is correct, and the greater the significance of your results.
3. One-Sided vs. Two-Sided Testing
When it’s time to test your hypothesis, it’s important to leverage the correct testing method. The two most common hypothesis testing methods are one-sided and two-sided tests , or one-tailed and two-tailed tests, respectively.
Typically, you’d leverage a one-sided test when you have a strong conviction about the direction of change you expect to see due to your hypothesis test. You’d leverage a two-sided test when you’re less confident in the direction of change.

4. Sampling
To perform hypothesis testing in the first place, you need to collect a sample of data to be analyzed. Depending on the question you’re seeking to answer or investigate, you might collect samples through surveys, observational studies, or experiments.
A survey involves asking a series of questions to a random population sample and recording self-reported responses.
Observational studies involve a researcher observing a sample population and collecting data as it occurs naturally, without intervention.
Finally, an experiment involves dividing a sample into multiple groups, one of which acts as the control group. For each non-control group, the variable being studied is manipulated to determine how the data collected differs from that of the control group.

Learn How to Perform Hypothesis Testing
Hypothesis testing is a complex process involving different moving pieces that can allow an organization to effectively leverage its data and inform strategic decisions.
If you’re interested in better understanding hypothesis testing and the role it can play within your organization, one option is to complete a course that focuses on the process. Doing so can lay the statistical and analytical foundation you need to succeed.
Do you want to learn more about hypothesis testing? Explore Business Analytics —one of our online business essentials courses —and download our Beginner’s Guide to Data & Analytics .

About the Author
Tutorial Playlist
Statistics tutorial, everything you need to know about the probability density function in statistics, the best guide to understand central limit theorem, an in-depth guide to measures of central tendency : mean, median and mode, the ultimate guide to understand conditional probability.
A Comprehensive Look at Percentile in Statistics
The Best Guide to Understand Bayes Theorem
Everything you need to know about the normal distribution, an in-depth explanation of cumulative distribution function, a complete guide to chi-square test, what is hypothesis testing in statistics types and examples, understanding the fundamentals of arithmetic and geometric progression, the definitive guide to understand spearman’s rank correlation, mean squared error: overview, examples, concepts and more, all you need to know about the empirical rule in statistics, the complete guide to skewness and kurtosis, a holistic look at bernoulli distribution.
All You Need to Know About Bias in Statistics
A Complete Guide to Get a Grasp of Time Series Analysis
The Key Differences Between Z-Test Vs. T-Test
The Complete Guide to Understand Pearson's Correlation
A complete guide on the types of statistical studies, everything you need to know about poisson distribution, your best guide to understand correlation vs. regression, the most comprehensive guide for beginners on what is correlation, hypothesis testing in statistics - types | examples.
Lesson 10 of 24 By Avijeet Biswal

Table of Contents
In today’s data-driven world, decisions are based on data all the time. Hypothesis plays a crucial role in that process, whether it may be making business decisions, in the health sector, academia, or in quality improvement. Without hypothesis & hypothesis tests, you risk drawing the wrong conclusions and making bad decisions. In this tutorial, you will look at Hypothesis Testing in Statistics.
The Ultimate Ticket to Top Data Science Job Roles
What Is Hypothesis Testing in Statistics?
Hypothesis Testing is a type of statistical analysis in which you put your assumptions about a population parameter to the test. It is used to estimate the relationship between 2 statistical variables.
Let's discuss few examples of statistical hypothesis from real-life -
- A teacher assumes that 60% of his college's students come from lower-middle-class families.
- A doctor believes that 3D (Diet, Dose, and Discipline) is 90% effective for diabetic patients.
Now that you know about hypothesis testing, look at the two types of hypothesis testing in statistics.
Hypothesis Testing Formula
Z = ( x̅ – μ0 ) / (σ /√n)
- Here, x̅ is the sample mean,
- μ0 is the population mean,
- σ is the standard deviation,
- n is the sample size.
How Hypothesis Testing Works?
An analyst performs hypothesis testing on a statistical sample to present evidence of the plausibility of the null hypothesis. Measurements and analyses are conducted on a random sample of the population to test a theory. Analysts use a random population sample to test two hypotheses: the null and alternative hypotheses.
The null hypothesis is typically an equality hypothesis between population parameters; for example, a null hypothesis may claim that the population means return equals zero. The alternate hypothesis is essentially the inverse of the null hypothesis (e.g., the population means the return is not equal to zero). As a result, they are mutually exclusive, and only one can be correct. One of the two possibilities, however, will always be correct.
Your Dream Career is Just Around The Corner!
Null Hypothesis and Alternative Hypothesis
The Null Hypothesis is the assumption that the event will not occur. A null hypothesis has no bearing on the study's outcome unless it is rejected.
H0 is the symbol for it, and it is pronounced H-naught.
The Alternate Hypothesis is the logical opposite of the null hypothesis. The acceptance of the alternative hypothesis follows the rejection of the null hypothesis. H1 is the symbol for it.
Let's understand this with an example.
A sanitizer manufacturer claims that its product kills 95 percent of germs on average.
To put this company's claim to the test, create a null and alternate hypothesis.
H0 (Null Hypothesis): Average = 95%.
Alternative Hypothesis (H1): The average is less than 95%.
Another straightforward example to understand this concept is determining whether or not a coin is fair and balanced. The null hypothesis states that the probability of a show of heads is equal to the likelihood of a show of tails. In contrast, the alternate theory states that the probability of a show of heads and tails would be very different.
Become a Data Scientist with Hands-on Training!
Hypothesis Testing Calculation With Examples
Let's consider a hypothesis test for the average height of women in the United States. Suppose our null hypothesis is that the average height is 5'4". We gather a sample of 100 women and determine that their average height is 5'5". The standard deviation of population is 2.
To calculate the z-score, we would use the following formula:
z = ( x̅ – μ0 ) / (σ /√n)
z = (5'5" - 5'4") / (2" / √100)
z = 0.5 / (0.045)
We will reject the null hypothesis as the z-score of 11.11 is very large and conclude that there is evidence to suggest that the average height of women in the US is greater than 5'4".
Steps in Hypothesis Testing
Hypothesis testing is a statistical method to determine if there is enough evidence in a sample of data to infer that a certain condition is true for the entire population. Here’s a breakdown of the typical steps involved in hypothesis testing:
Formulate Hypotheses
- Null Hypothesis (H0): This hypothesis states that there is no effect or difference, and it is the hypothesis you attempt to reject with your test.
- Alternative Hypothesis (H1 or Ha): This hypothesis is what you might believe to be true or hope to prove true. It is usually considered the opposite of the null hypothesis.
Choose the Significance Level (α)
The significance level, often denoted by alpha (α), is the probability of rejecting the null hypothesis when it is true. Common choices for α are 0.05 (5%), 0.01 (1%), and 0.10 (10%).
Select the Appropriate Test
Choose a statistical test based on the type of data and the hypothesis. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis. The selection depends on data type, distribution, sample size, and whether the hypothesis is one-tailed or two-tailed.
Collect Data
Gather the data that will be analyzed in the test. This data should be representative of the population to infer conclusions accurately.
Calculate the Test Statistic
Based on the collected data and the chosen test, calculate a test statistic that reflects how much the observed data deviates from the null hypothesis.
Determine the p-value
The p-value is the probability of observing test results at least as extreme as the results observed, assuming the null hypothesis is correct. It helps determine the strength of the evidence against the null hypothesis.
Make a Decision
Compare the p-value to the chosen significance level:
- If the p-value ≤ α: Reject the null hypothesis, suggesting sufficient evidence in the data supports the alternative hypothesis.
- If the p-value > α: Do not reject the null hypothesis, suggesting insufficient evidence to support the alternative hypothesis.
Report the Results
Present the findings from the hypothesis test, including the test statistic, p-value, and the conclusion about the hypotheses.
Perform Post-hoc Analysis (if necessary)
Depending on the results and the study design, further analysis may be needed to explore the data more deeply or to address multiple comparisons if several hypotheses were tested simultaneously.
Types of Hypothesis Testing
To determine whether a discovery or relationship is statistically significant, hypothesis testing uses a z-test. It usually checks to see if two means are the same (the null hypothesis). Only when the population standard deviation is known and the sample size is 30 data points or more, can a z-test be applied.
A statistical test called a t-test is employed to compare the means of two groups. To determine whether two groups differ or if a procedure or treatment affects the population of interest, it is frequently used in hypothesis testing.
Chi-Square
You utilize a Chi-square test for hypothesis testing concerning whether your data is as predicted. To determine if the expected and observed results are well-fitted, the Chi-square test analyzes the differences between categorical variables from a random sample. The test's fundamental premise is that the observed values in your data should be compared to the predicted values that would be present if the null hypothesis were true.
Hypothesis Testing and Confidence Intervals
Both confidence intervals and hypothesis tests are inferential techniques that depend on approximating the sample distribution. Data from a sample is used to estimate a population parameter using confidence intervals. Data from a sample is used in hypothesis testing to examine a given hypothesis. We must have a postulated parameter to conduct hypothesis testing.
Bootstrap distributions and randomization distributions are created using comparable simulation techniques. The observed sample statistic is the focal point of a bootstrap distribution, whereas the null hypothesis value is the focal point of a randomization distribution.
A variety of feasible population parameter estimates are included in confidence ranges. In this lesson, we created just two-tailed confidence intervals. There is a direct connection between these two-tail confidence intervals and these two-tail hypothesis tests. The results of a two-tailed hypothesis test and two-tailed confidence intervals typically provide the same results. In other words, a hypothesis test at the 0.05 level will virtually always fail to reject the null hypothesis if the 95% confidence interval contains the predicted value. A hypothesis test at the 0.05 level will nearly certainly reject the null hypothesis if the 95% confidence interval does not include the hypothesized parameter.
Become a Data Scientist through hands-on learning with hackathons, masterclasses, webinars, and Ask-Me-Anything! Start learning now!
Simple and Composite Hypothesis Testing
Depending on the population distribution, you can classify the statistical hypothesis into two types.
Simple Hypothesis: A simple hypothesis specifies an exact value for the parameter.
Composite Hypothesis: A composite hypothesis specifies a range of values.
A company is claiming that their average sales for this quarter are 1000 units. This is an example of a simple hypothesis.
Suppose the company claims that the sales are in the range of 900 to 1000 units. Then this is a case of a composite hypothesis.
One-Tailed and Two-Tailed Hypothesis Testing
The One-Tailed test, also called a directional test, considers a critical region of data that would result in the null hypothesis being rejected if the test sample falls into it, inevitably meaning the acceptance of the alternate hypothesis.
In a one-tailed test, the critical distribution area is one-sided, meaning the test sample is either greater or lesser than a specific value.
In two tails, the test sample is checked to be greater or less than a range of values in a Two-Tailed test, implying that the critical distribution area is two-sided.
If the sample falls within this range, the alternate hypothesis will be accepted, and the null hypothesis will be rejected.
Become a Data Scientist With Real-World Experience
Right Tailed Hypothesis Testing
If the larger than (>) sign appears in your hypothesis statement, you are using a right-tailed test, also known as an upper test. Or, to put it another way, the disparity is to the right. For instance, you can contrast the battery life before and after a change in production. Your hypothesis statements can be the following if you want to know if the battery life is longer than the original (let's say 90 hours):
- The null hypothesis is (H0 <= 90) or less change.
- A possibility is that battery life has risen (H1) > 90.
The crucial point in this situation is that the alternate hypothesis (H1), not the null hypothesis, decides whether you get a right-tailed test.
Left Tailed Hypothesis Testing
Alternative hypotheses that assert the true value of a parameter is lower than the null hypothesis are tested with a left-tailed test; they are indicated by the asterisk "<".
Suppose H0: mean = 50 and H1: mean not equal to 50
According to the H1, the mean can be greater than or less than 50. This is an example of a Two-tailed test.
In a similar manner, if H0: mean >=50, then H1: mean <50
Here the mean is less than 50. It is called a One-tailed test.
Type 1 and Type 2 Error
A hypothesis test can result in two types of errors.
Type 1 Error: A Type-I error occurs when sample results reject the null hypothesis despite being true.
Type 2 Error: A Type-II error occurs when the null hypothesis is not rejected when it is false, unlike a Type-I error.
Suppose a teacher evaluates the examination paper to decide whether a student passes or fails.
H0: Student has passed
H1: Student has failed
Type I error will be the teacher failing the student [rejects H0] although the student scored the passing marks [H0 was true].
Type II error will be the case where the teacher passes the student [do not reject H0] although the student did not score the passing marks [H1 is true].
Our Data Scientist Master's Program covers core topics such as R, Python, Machine Learning, Tableau, Hadoop, and Spark. Get started on your journey today!
Limitations of Hypothesis Testing
Hypothesis testing has some limitations that researchers should be aware of:
- It cannot prove or establish the truth: Hypothesis testing provides evidence to support or reject a hypothesis, but it cannot confirm the absolute truth of the research question.
- Results are sample-specific: Hypothesis testing is based on analyzing a sample from a population, and the conclusions drawn are specific to that particular sample.
- Possible errors: During hypothesis testing, there is a chance of committing type I error (rejecting a true null hypothesis) or type II error (failing to reject a false null hypothesis).
- Assumptions and requirements: Different tests have specific assumptions and requirements that must be met to accurately interpret results.
Learn All The Tricks Of The BI Trade
After reading this tutorial, you would have a much better understanding of hypothesis testing, one of the most important concepts in the field of Data Science . The majority of hypotheses are based on speculation about observed behavior, natural phenomena, or established theories.
If you are interested in statistics of data science and skills needed for such a career, you ought to explore the Post Graduate Program in Data Science.
If you have any questions regarding this ‘Hypothesis Testing In Statistics’ tutorial, do share them in the comment section. Our subject matter expert will respond to your queries. Happy learning!
1. What is hypothesis testing in statistics with example?
Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to assess the evidence. An example: testing if a new drug improves patient recovery (Ha) compared to the standard treatment (H0) based on collected patient data.
2. What is H0 and H1 in statistics?
In statistics, H0 and H1 represent the null and alternative hypotheses. The null hypothesis, H0, is the default assumption that no effect or difference exists between groups or conditions. The alternative hypothesis, H1, is the competing claim suggesting an effect or a difference. Statistical tests determine whether to reject the null hypothesis in favor of the alternative hypothesis based on the data.
3. What is a simple hypothesis with an example?
A simple hypothesis is a specific statement predicting a single relationship between two variables. It posits a direct and uncomplicated outcome. For example, a simple hypothesis might state, "Increased sunlight exposure increases the growth rate of sunflowers." Here, the hypothesis suggests a direct relationship between the amount of sunlight (independent variable) and the growth rate of sunflowers (dependent variable), with no additional variables considered.
4. What are the 3 major types of hypothesis?
The three major types of hypotheses are:
- Null Hypothesis (H0): Represents the default assumption, stating that there is no significant effect or relationship in the data.
- Alternative Hypothesis (Ha): Contradicts the null hypothesis and proposes a specific effect or relationship that researchers want to investigate.
- Nondirectional Hypothesis: An alternative hypothesis that doesn't specify the direction of the effect, leaving it open for both positive and negative possibilities.
Find our PL-300 Microsoft Power BI Certification Training Online Classroom training classes in top cities:
| Name | Date | Place | |
|---|---|---|---|
| 21 Sep -6 Oct 2024, Weekend batch | Your City | ||
| 12 Oct -27 Oct 2024, Weekend batch | Your City | ||
| 26 Oct -10 Nov 2024, Weekend batch | Your City |
About the Author
Avijeet is a Senior Research Analyst at Simplilearn. Passionate about Data Analytics, Machine Learning, and Deep Learning, Avijeet is also interested in politics, cricket, and football.
Recommended Resources
Free eBook: Top Programming Languages For A Data Scientist
Normality Test in Minitab: Minitab with Statistics
Machine Learning Career Guide: A Playbook to Becoming a Machine Learning Engineer
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
The Beginner's Guide to Statistical Analysis | 5 Steps & Examples
Statistical analysis means investigating trends, patterns, and relationships using quantitative data . It is an important research tool used by scientists, governments, businesses, and other organizations.
To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process . You need to specify your hypotheses and make decisions about your research design, sample size, and sampling procedure.
After collecting data from your sample, you can organize and summarize the data using descriptive statistics . Then, you can use inferential statistics to formally test hypotheses and make estimates about the population. Finally, you can interpret and generalize your findings.
This article is a practical introduction to statistical analysis for students and researchers. We’ll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between variables.
Table of contents
Step 1: write your hypotheses and plan your research design, step 2: collect data from a sample, step 3: summarize your data with descriptive statistics, step 4: test hypotheses or make estimates with inferential statistics, step 5: interpret your results, other interesting articles.
To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design.
Writing statistical hypotheses
The goal of research is often to investigate a relationship between variables within a population . You start with a prediction, and use statistical analysis to test that prediction.
A statistical hypothesis is a formal way of writing a prediction about a population. Every research prediction is rephrased into null and alternative hypotheses that can be tested using sample data.
While the null hypothesis always predicts no effect or no relationship between variables, the alternative hypothesis states your research prediction of an effect or relationship.
- Null hypothesis: A 5-minute meditation exercise will have no effect on math test scores in teenagers.
- Alternative hypothesis: A 5-minute meditation exercise will improve math test scores in teenagers.
- Null hypothesis: Parental income and GPA have no relationship with each other in college students.
- Alternative hypothesis: Parental income and GPA are positively correlated in college students.
Planning your research design
A research design is your overall strategy for data collection and analysis. It determines the statistical tests you can use to test your hypothesis later on.
First, decide whether your research will use a descriptive, correlational, or experimental design. Experiments directly influence variables, whereas descriptive and correlational studies only measure variables.
- In an experimental design , you can assess a cause-and-effect relationship (e.g., the effect of meditation on test scores) using statistical tests of comparison or regression.
- In a correlational design , you can explore relationships between variables (e.g., parental income and GPA) without any assumption of causality using correlation coefficients and significance tests.
- In a descriptive design , you can study the characteristics of a population or phenomenon (e.g., the prevalence of anxiety in U.S. college students) using statistical tests to draw inferences from sample data.
Your research design also concerns whether you’ll compare participants at the group level or individual level, or both.
- In a between-subjects design , you compare the group-level outcomes of participants who have been exposed to different treatments (e.g., those who performed a meditation exercise vs those who didn’t).
- In a within-subjects design , you compare repeated measures from participants who have participated in all treatments of a study (e.g., scores from before and after performing a meditation exercise).
- In a mixed (factorial) design , one variable is altered between subjects and another is altered within subjects (e.g., pretest and posttest scores from participants who either did or didn’t do a meditation exercise).
- Experimental
- Correlational
First, you’ll take baseline test scores from participants. Then, your participants will undergo a 5-minute meditation exercise. Finally, you’ll record participants’ scores from a second math test.
In this experiment, the independent variable is the 5-minute meditation exercise, and the dependent variable is the math test score from before and after the intervention. Example: Correlational research design In a correlational study, you test whether there is a relationship between parental income and GPA in graduating college students. To collect your data, you will ask participants to fill in a survey and self-report their parents’ incomes and their own GPA.
Measuring variables
When planning a research design, you should operationalize your variables and decide exactly how you will measure them.
For statistical analysis, it’s important to consider the level of measurement of your variables, which tells you what kind of data they contain:
- Categorical data represents groupings. These may be nominal (e.g., gender) or ordinal (e.g. level of language ability).
- Quantitative data represents amounts. These may be on an interval scale (e.g. test score) or a ratio scale (e.g. age).
Many variables can be measured at different levels of precision. For example, age data can be quantitative (8 years old) or categorical (young). If a variable is coded numerically (e.g., level of agreement from 1–5), it doesn’t automatically mean that it’s quantitative instead of categorical.
Identifying the measurement level is important for choosing appropriate statistics and hypothesis tests. For example, you can calculate a mean score with quantitative data, but not with categorical data.
In a research study, along with measures of your variables of interest, you’ll often collect data on relevant participant characteristics.
| Variable | Type of data |
|---|---|
| Age | Quantitative (ratio) |
| Gender | Categorical (nominal) |
| Race or ethnicity | Categorical (nominal) |
| Baseline test scores | Quantitative (interval) |
| Final test scores | Quantitative (interval) |
| Parental income | Quantitative (ratio) |
|---|---|
| GPA | Quantitative (interval) |
Prevent plagiarism. Run a free check.

In most cases, it’s too difficult or expensive to collect data from every member of the population you’re interested in studying. Instead, you’ll collect data from a sample.
Statistical analysis allows you to apply your findings beyond your own sample as long as you use appropriate sampling procedures . You should aim for a sample that is representative of the population.
Sampling for statistical analysis
There are two main approaches to selecting a sample.
- Probability sampling: every member of the population has a chance of being selected for the study through random selection.
- Non-probability sampling: some members of the population are more likely than others to be selected for the study because of criteria such as convenience or voluntary self-selection.
In theory, for highly generalizable findings, you should use a probability sampling method. Random selection reduces several types of research bias , like sampling bias , and ensures that data from your sample is actually typical of the population. Parametric tests can be used to make strong statistical inferences when data are collected using probability sampling.
But in practice, it’s rarely possible to gather the ideal sample. While non-probability samples are more likely to at risk for biases like self-selection bias , they are much easier to recruit and collect data from. Non-parametric tests are more appropriate for non-probability samples, but they result in weaker inferences about the population.
If you want to use parametric tests for non-probability samples, you have to make the case that:
- your sample is representative of the population you’re generalizing your findings to.
- your sample lacks systematic bias.
Keep in mind that external validity means that you can only generalize your conclusions to others who share the characteristics of your sample. For instance, results from Western, Educated, Industrialized, Rich and Democratic samples (e.g., college students in the US) aren’t automatically applicable to all non-WEIRD populations.
If you apply parametric tests to data from non-probability samples, be sure to elaborate on the limitations of how far your results can be generalized in your discussion section .
Create an appropriate sampling procedure
Based on the resources available for your research, decide on how you’ll recruit participants.
- Will you have resources to advertise your study widely, including outside of your university setting?
- Will you have the means to recruit a diverse sample that represents a broad population?
- Do you have time to contact and follow up with members of hard-to-reach groups?
Your participants are self-selected by their schools. Although you’re using a non-probability sample, you aim for a diverse and representative sample. Example: Sampling (correlational study) Your main population of interest is male college students in the US. Using social media advertising, you recruit senior-year male college students from a smaller subpopulation: seven universities in the Boston area.
Calculate sufficient sample size
Before recruiting participants, decide on your sample size either by looking at other studies in your field or using statistics. A sample that’s too small may be unrepresentative of the sample, while a sample that’s too large will be more costly than necessary.
There are many sample size calculators online. Different formulas are used depending on whether you have subgroups or how rigorous your study should be (e.g., in clinical research). As a rule of thumb, a minimum of 30 units or more per subgroup is necessary.
To use these calculators, you have to understand and input these key components:
- Significance level (alpha): the risk of rejecting a true null hypothesis that you are willing to take, usually set at 5%.
- Statistical power : the probability of your study detecting an effect of a certain size if there is one, usually 80% or higher.
- Expected effect size : a standardized indication of how large the expected result of your study will be, usually based on other similar studies.
- Population standard deviation: an estimate of the population parameter based on a previous study or a pilot study of your own.
Once you’ve collected all of your data, you can inspect them and calculate descriptive statistics that summarize them.
Inspect your data
There are various ways to inspect your data, including the following:
- Organizing data from each variable in frequency distribution tables .
- Displaying data from a key variable in a bar chart to view the distribution of responses.
- Visualizing the relationship between two variables using a scatter plot .
By visualizing your data in tables and graphs, you can assess whether your data follow a skewed or normal distribution and whether there are any outliers or missing data.
A normal distribution means that your data are symmetrically distributed around a center where most values lie, with the values tapering off at the tail ends.

In contrast, a skewed distribution is asymmetric and has more values on one end than the other. The shape of the distribution is important to keep in mind because only some descriptive statistics should be used with skewed distributions.
Extreme outliers can also produce misleading statistics, so you may need a systematic approach to dealing with these values.
Calculate measures of central tendency
Measures of central tendency describe where most of the values in a data set lie. Three main measures of central tendency are often reported:
- Mode : the most popular response or value in the data set.
- Median : the value in the exact middle of the data set when ordered from low to high.
- Mean : the sum of all values divided by the number of values.
However, depending on the shape of the distribution and level of measurement, only one or two of these measures may be appropriate. For example, many demographic characteristics can only be described using the mode or proportions, while a variable like reaction time may not have a mode at all.
Calculate measures of variability
Measures of variability tell you how spread out the values in a data set are. Four main measures of variability are often reported:
- Range : the highest value minus the lowest value of the data set.
- Interquartile range : the range of the middle half of the data set.
- Standard deviation : the average distance between each value in your data set and the mean.
- Variance : the square of the standard deviation.
Once again, the shape of the distribution and level of measurement should guide your choice of variability statistics. The interquartile range is the best measure for skewed distributions, while standard deviation and variance provide the best information for normal distributions.
Using your table, you should check whether the units of the descriptive statistics are comparable for pretest and posttest scores. For example, are the variance levels similar across the groups? Are there any extreme values? If there are, you may need to identify and remove extreme outliers in your data set or transform your data before performing a statistical test.
| Pretest scores | Posttest scores | |
|---|---|---|
| Mean | 68.44 | 75.25 |
| Standard deviation | 9.43 | 9.88 |
| Variance | 88.96 | 97.96 |
| Range | 36.25 | 45.12 |
| 30 | ||
From this table, we can see that the mean score increased after the meditation exercise, and the variances of the two scores are comparable. Next, we can perform a statistical test to find out if this improvement in test scores is statistically significant in the population. Example: Descriptive statistics (correlational study) After collecting data from 653 students, you tabulate descriptive statistics for annual parental income and GPA.
It’s important to check whether you have a broad range of data points. If you don’t, your data may be skewed towards some groups more than others (e.g., high academic achievers), and only limited inferences can be made about a relationship.
| Parental income (USD) | GPA | |
|---|---|---|
| Mean | 62,100 | 3.12 |
| Standard deviation | 15,000 | 0.45 |
| Variance | 225,000,000 | 0.16 |
| Range | 8,000–378,000 | 2.64–4.00 |
| 653 | ||
A number that describes a sample is called a statistic , while a number describing a population is called a parameter . Using inferential statistics , you can make conclusions about population parameters based on sample statistics.
Researchers often use two main methods (simultaneously) to make inferences in statistics.
- Estimation: calculating population parameters based on sample statistics.
- Hypothesis testing: a formal process for testing research predictions about the population using samples.
You can make two types of estimates of population parameters from sample statistics:
- A point estimate : a value that represents your best guess of the exact parameter.
- An interval estimate : a range of values that represent your best guess of where the parameter lies.
If your aim is to infer and report population characteristics from sample data, it’s best to use both point and interval estimates in your paper.
You can consider a sample statistic a point estimate for the population parameter when you have a representative sample (e.g., in a wide public opinion poll, the proportion of a sample that supports the current government is taken as the population proportion of government supporters).
There’s always error involved in estimation, so you should also provide a confidence interval as an interval estimate to show the variability around a point estimate.
A confidence interval uses the standard error and the z score from the standard normal distribution to convey where you’d generally expect to find the population parameter most of the time.
Hypothesis testing
Using data from a sample, you can test hypotheses about relationships between variables in the population. Hypothesis testing starts with the assumption that the null hypothesis is true in the population, and you use statistical tests to assess whether the null hypothesis can be rejected or not.
Statistical tests determine where your sample data would lie on an expected distribution of sample data if the null hypothesis were true. These tests give two main outputs:
- A test statistic tells you how much your data differs from the null hypothesis of the test.
- A p value tells you the likelihood of obtaining your results if the null hypothesis is actually true in the population.
Statistical tests come in three main varieties:
- Comparison tests assess group differences in outcomes.
- Regression tests assess cause-and-effect relationships between variables.
- Correlation tests assess relationships between variables without assuming causation.
Your choice of statistical test depends on your research questions, research design, sampling method, and data characteristics.
Parametric tests
Parametric tests make powerful inferences about the population based on sample data. But to use them, some assumptions must be met, and only some types of variables can be used. If your data violate these assumptions, you can perform appropriate data transformations or use alternative non-parametric tests instead.
A regression models the extent to which changes in a predictor variable results in changes in outcome variable(s).
- A simple linear regression includes one predictor variable and one outcome variable.
- A multiple linear regression includes two or more predictor variables and one outcome variable.
Comparison tests usually compare the means of groups. These may be the means of different groups within a sample (e.g., a treatment and control group), the means of one sample group taken at different times (e.g., pretest and posttest scores), or a sample mean and a population mean.
- A t test is for exactly 1 or 2 groups when the sample is small (30 or less).
- A z test is for exactly 1 or 2 groups when the sample is large.
- An ANOVA is for 3 or more groups.
The z and t tests have subtypes based on the number and types of samples and the hypotheses:
- If you have only one sample that you want to compare to a population mean, use a one-sample test .
- If you have paired measurements (within-subjects design), use a dependent (paired) samples test .
- If you have completely separate measurements from two unmatched groups (between-subjects design), use an independent (unpaired) samples test .
- If you expect a difference between groups in a specific direction, use a one-tailed test .
- If you don’t have any expectations for the direction of a difference between groups, use a two-tailed test .
The only parametric correlation test is Pearson’s r . The correlation coefficient ( r ) tells you the strength of a linear relationship between two quantitative variables.
However, to test whether the correlation in the sample is strong enough to be important in the population, you also need to perform a significance test of the correlation coefficient, usually a t test, to obtain a p value. This test uses your sample size to calculate how much the correlation coefficient differs from zero in the population.
You use a dependent-samples, one-tailed t test to assess whether the meditation exercise significantly improved math test scores. The test gives you:
- a t value (test statistic) of 3.00
- a p value of 0.0028
Although Pearson’s r is a test statistic, it doesn’t tell you anything about how significant the correlation is in the population. You also need to test whether this sample correlation coefficient is large enough to demonstrate a correlation in the population.
A t test can also determine how significantly a correlation coefficient differs from zero based on sample size. Since you expect a positive correlation between parental income and GPA, you use a one-sample, one-tailed t test. The t test gives you:
- a t value of 3.08
- a p value of 0.001
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
The final step of statistical analysis is interpreting your results.
Statistical significance
In hypothesis testing, statistical significance is the main criterion for forming conclusions. You compare your p value to a set significance level (usually 0.05) to decide whether your results are statistically significant or non-significant.
Statistically significant results are considered unlikely to have arisen solely due to chance. There is only a very low chance of such a result occurring if the null hypothesis is true in the population.
This means that you believe the meditation intervention, rather than random factors, directly caused the increase in test scores. Example: Interpret your results (correlational study) You compare your p value of 0.001 to your significance threshold of 0.05. With a p value under this threshold, you can reject the null hypothesis. This indicates a statistically significant correlation between parental income and GPA in male college students.
Note that correlation doesn’t always mean causation, because there are often many underlying factors contributing to a complex variable like GPA. Even if one variable is related to another, this may be because of a third variable influencing both of them, or indirect links between the two variables.
Effect size
A statistically significant result doesn’t necessarily mean that there are important real life applications or clinical outcomes for a finding.
In contrast, the effect size indicates the practical significance of your results. It’s important to report effect sizes along with your inferential statistics for a complete picture of your results. You should also report interval estimates of effect sizes if you’re writing an APA style paper .
With a Cohen’s d of 0.72, there’s medium to high practical significance to your finding that the meditation exercise improved test scores. Example: Effect size (correlational study) To determine the effect size of the correlation coefficient, you compare your Pearson’s r value to Cohen’s effect size criteria.
Decision errors
Type I and Type II errors are mistakes made in research conclusions. A Type I error means rejecting the null hypothesis when it’s actually true, while a Type II error means failing to reject the null hypothesis when it’s false.
You can aim to minimize the risk of these errors by selecting an optimal significance level and ensuring high power . However, there’s a trade-off between the two errors, so a fine balance is necessary.
Frequentist versus Bayesian statistics
Traditionally, frequentist statistics emphasizes null hypothesis significance testing and always starts with the assumption of a true null hypothesis.
However, Bayesian statistics has grown in popularity as an alternative approach in the last few decades. In this approach, you use previous research to continually update your hypotheses based on your expectations and observations.
Bayes factor compares the relative strength of evidence for the null versus the alternative hypothesis rather than making a conclusion about rejecting the null hypothesis or not.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
Methodology
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Likert scale
Research bias
- Implicit bias
- Framing effect
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hostile attribution bias
- Affect heuristic
Is this article helpful?
Other students also liked.
- Descriptive Statistics | Definitions, Types, Examples
- Inferential Statistics | An Easy Introduction & Examples
- Choosing the Right Statistical Test | Types & Examples
More interesting articles
- Akaike Information Criterion | When & How to Use It (Example)
- An Easy Introduction to Statistical Significance (With Examples)
- An Introduction to t Tests | Definitions, Formula and Examples
- ANOVA in R | A Complete Step-by-Step Guide with Examples
- Central Limit Theorem | Formula, Definition & Examples
- Central Tendency | Understanding the Mean, Median & Mode
- Chi-Square (Χ²) Distributions | Definition & Examples
- Chi-Square (Χ²) Table | Examples & Downloadable Table
- Chi-Square (Χ²) Tests | Types, Formula & Examples
- Chi-Square Goodness of Fit Test | Formula, Guide & Examples
- Chi-Square Test of Independence | Formula, Guide & Examples
- Coefficient of Determination (R²) | Calculation & Interpretation
- Correlation Coefficient | Types, Formulas & Examples
- Frequency Distribution | Tables, Types & Examples
- How to Calculate Standard Deviation (Guide) | Calculator & Examples
- How to Calculate Variance | Calculator, Analysis & Examples
- How to Find Degrees of Freedom | Definition & Formula
- How to Find Interquartile Range (IQR) | Calculator & Examples
- How to Find Outliers | 4 Ways with Examples & Explanation
- How to Find the Geometric Mean | Calculator & Formula
- How to Find the Mean | Definition, Examples & Calculator
- How to Find the Median | Definition, Examples & Calculator
- How to Find the Mode | Definition, Examples & Calculator
- How to Find the Range of a Data Set | Calculator & Formula
- Hypothesis Testing | A Step-by-Step Guide with Easy Examples
- Interval Data and How to Analyze It | Definitions & Examples
- Levels of Measurement | Nominal, Ordinal, Interval and Ratio
- Linear Regression in R | A Step-by-Step Guide & Examples
- Missing Data | Types, Explanation, & Imputation
- Multiple Linear Regression | A Quick Guide (Examples)
- Nominal Data | Definition, Examples, Data Collection & Analysis
- Normal Distribution | Examples, Formulas, & Uses
- Null and Alternative Hypotheses | Definitions & Examples
- One-way ANOVA | When and How to Use It (With Examples)
- Ordinal Data | Definition, Examples, Data Collection & Analysis
- Parameter vs Statistic | Definitions, Differences & Examples
- Pearson Correlation Coefficient (r) | Guide & Examples
- Poisson Distributions | Definition, Formula & Examples
- Probability Distribution | Formula, Types, & Examples
- Quartiles & Quantiles | Calculation, Definition & Interpretation
- Ratio Scales | Definition, Examples, & Data Analysis
- Simple Linear Regression | An Easy Introduction & Examples
- Skewness | Definition, Examples & Formula
- Statistical Power and Why It Matters | A Simple Introduction
- Student's t Table (Free Download) | Guide & Examples
- T-distribution: What it is and how to use it
- Test statistics | Definition, Interpretation, and Examples
- The Standard Normal Distribution | Calculator, Examples & Uses
- Two-Way ANOVA | Examples & When To Use It
- Type I & Type II Errors | Differences, Examples, Visualizations
- Understanding Confidence Intervals | Easy Examples & Formulas
- Understanding P values | Definition and Examples
- Variability | Calculating Range, IQR, Variance, Standard Deviation
- What is Effect Size and Why Does It Matter? (Examples)
- What Is Kurtosis? | Definition, Examples & Formula
- What Is Standard Error? | How to Calculate (Guide with Examples)
What is your plagiarism score?
Hypothesis Testing
About hypothesis testing.
Watch the video for a brief overview of hypothesis testing:

Can’t see the video? Click here to watch it on YouTube.
Contents (Click to skip to the section):
What is a Hypothesis?
What is hypothesis testing.
- Hypothesis Testing Examples (One Sample Z Test).
- Hypothesis Test on a Mean (TI 83).
Bayesian Hypothesis Testing.
- More Hypothesis Testing Articles
- Hypothesis Tests in One Picture
- Critical Values
What is the Null Hypothesis?
Need help with a homework problem? Check out our tutoring page!

A hypothesis is an educated guess about something in the world around you. It should be testable, either by experiment or observation. For example:
- A new medicine you think might work.
- A way of teaching you think might be better.
- A possible location of new species.
- A fairer way to administer standardized tests.
It can really be anything at all as long as you can put it to the test.
What is a Hypothesis Statement?
If you are going to propose a hypothesis, it’s customary to write a statement. Your statement will look like this: “If I…(do this to an independent variable )….then (this will happen to the dependent variable ).” For example:
- If I (decrease the amount of water given to herbs) then (the herbs will increase in size).
- If I (give patients counseling in addition to medication) then (their overall depression scale will decrease).
- If I (give exams at noon instead of 7) then (student test scores will improve).
- If I (look in this certain location) then (I am more likely to find new species).
A good hypothesis statement should:
- Include an “if” and “then” statement (according to the University of California).
- Include both the independent and dependent variables.
- Be testable by experiment, survey or other scientifically sound technique.
- Be based on information in prior research (either yours or someone else’s).
- Have design criteria (for engineering or programming projects).
Hypothesis testing can be one of the most confusing aspects for students, mostly because before you can even perform a test, you have to know what your null hypothesis is. Often, those tricky word problems that you are faced with can be difficult to decipher. But it’s easier than you think; all you need to do is:
- Figure out your null hypothesis,
- State your null hypothesis,
- Choose what kind of test you need to perform,
- Either support or reject the null hypothesis .
If you trace back the history of science, the null hypothesis is always the accepted fact. Simple examples of null hypotheses that are generally accepted as being true are:
- DNA is shaped like a double helix.
- There are 8 planets in the solar system (excluding Pluto).
- Taking Vioxx can increase your risk of heart problems (a drug now taken off the market).
How do I State the Null Hypothesis?
You won’t be required to actually perform a real experiment or survey in elementary statistics (or even disprove a fact like “Pluto is a planet”!), so you’ll be given word problems from real-life situations. You’ll need to figure out what your hypothesis is from the problem. This can be a little trickier than just figuring out what the accepted fact is. With word problems, you are looking to find a fact that is nullifiable (i.e. something you can reject).
Hypothesis Testing Examples #1: Basic Example
A researcher thinks that if knee surgery patients go to physical therapy twice a week (instead of 3 times), their recovery period will be longer. Average recovery times for knee surgery patients is 8.2 weeks.
The hypothesis statement in this question is that the researcher believes the average recovery time is more than 8.2 weeks. It can be written in mathematical terms as: H 1 : μ > 8.2
Next, you’ll need to state the null hypothesis . That’s what will happen if the researcher is wrong . In the above example, if the researcher is wrong then the recovery time is less than or equal to 8.2 weeks. In math, that’s: H 0 μ ≤ 8.2
Rejecting the null hypothesis
Ten or so years ago, we believed that there were 9 planets in the solar system. Pluto was demoted as a planet in 2006. The null hypothesis of “Pluto is a planet” was replaced by “Pluto is not a planet.” Of course, rejecting the null hypothesis isn’t always that easy— the hard part is usually figuring out what your null hypothesis is in the first place.
Hypothesis Testing Examples (One Sample Z Test)
The one sample z test isn’t used very often (because we rarely know the actual population standard deviation ). However, it’s a good idea to understand how it works as it’s one of the simplest tests you can perform in hypothesis testing. In English class you got to learn the basics (like grammar and spelling) before you could write a story; think of one sample z tests as the foundation for understanding more complex hypothesis testing. This page contains two hypothesis testing examples for one sample z-tests .
One Sample Hypothesis Testing Example: One Tailed Z Test
Watch the video for an example:

A principal at a certain school claims that the students in his school are above average intelligence. A random sample of thirty students IQ scores have a mean score of 112.5. Is there sufficient evidence to support the principal’s claim? The mean population IQ is 100 with a standard deviation of 15.
Step 1: State the Null hypothesis . The accepted fact is that the population mean is 100, so: H 0 : μ = 100.
Step 2: State the Alternate Hypothesis . The claim is that the students have above average IQ scores, so: H 1 : μ > 100. The fact that we are looking for scores “greater than” a certain point means that this is a one-tailed test.

Step 4: State the alpha level . If you aren’t given an alpha level , use 5% (0.05).
Step 5: Find the rejection region area (given by your alpha level above) from the z-table . An area of .05 is equal to a z-score of 1.645.

Step 6: If Step 6 is greater than Step 5, reject the null hypothesis. If it’s less than Step 5, you cannot reject the null hypothesis. In this case, it is more (4.56 > 1.645), so you can reject the null.
One Sample Hypothesis Testing Examples: #3
Watch the video for an example of a two-tailed z-test:
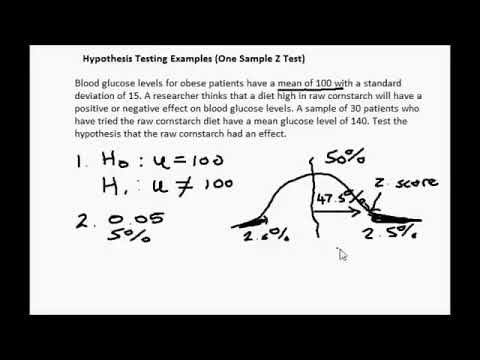
Blood glucose levels for obese patients have a mean of 100 with a standard deviation of 15. A researcher thinks that a diet high in raw cornstarch will have a positive or negative effect on blood glucose levels. A sample of 30 patients who have tried the raw cornstarch diet have a mean glucose level of 140. Test the hypothesis that the raw cornstarch had an effect.
- State the null hypothesis : H 0 :μ=100
- State the alternate hypothesis : H 1 :≠100
- State your alpha level. We’ll use 0.05 for this example. As this is a two-tailed test, split the alpha into two. 0.05/2=0.025
- Find the z-score associated with your alpha level . You’re looking for the area in one tail only . A z-score for 0.75(1-0.025=0.975) is 1.96. As this is a two-tailed test, you would also be considering the left tail (z = 1.96)
- If Step 5 is less than -1.96 or greater than 1.96 (Step 3), reject the null hypothesis . In this case, it is greater, so you can reject the null.
*This process is made much easier if you use a TI-83 or Excel to calculate the z-score (the “critical value”). See:
- Critical z value TI 83
- Z Score in Excel
Hypothesis Testing Examples: Mean (Using TI 83)
You can use the TI 83 calculator for hypothesis testing, but the calculator won’t figure out the null and alternate hypotheses; that’s up to you to read the question and input it into the calculator.
Example problem : A sample of 200 people has a mean age of 21 with a population standard deviation (σ) of 5. Test the hypothesis that the population mean is 18.9 at α = 0.05.
Step 1: State the null hypothesis. In this case, the null hypothesis is that the population mean is 18.9, so we write: H 0 : μ = 18.9
Step 2: State the alternative hypothesis. We want to know if our sample, which has a mean of 21 instead of 18.9, really is different from the population, therefore our alternate hypothesis: H 1 : μ ≠ 18.9
Step 3: Press Stat then press the right arrow twice to select TESTS.
Step 4: Press 1 to select 1:Z-Test… . Press ENTER.
Step 5: Use the right arrow to select Stats .
Step 6: Enter the data from the problem: μ 0 : 18.9 σ: 5 x : 21 n: 200 μ: ≠μ 0
Step 7: Arrow down to Calculate and press ENTER. The calculator shows the p-value: p = 2.87 × 10 -9
This is smaller than our alpha value of .05. That means we should reject the null hypothesis .
Bayesian Hypothesis Testing: What is it?

Bayesian hypothesis testing helps to answer the question: Can the results from a test or survey be repeated? Why do we care if a test can be repeated? Let’s say twenty people in the same village came down with leukemia. A group of researchers find that cell-phone towers are to blame. However, a second study found that cell-phone towers had nothing to do with the cancer cluster in the village. In fact, they found that the cancers were completely random. If that sounds impossible, it actually can happen! Clusters of cancer can happen simply by chance . There could be many reasons why the first study was faulty. One of the main reasons could be that they just didn’t take into account that sometimes things happen randomly and we just don’t know why.
It’s good science to let people know if your study results are solid, or if they could have happened by chance. The usual way of doing this is to test your results with a p-value . A p value is a number that you get by running a hypothesis test on your data. A P value of 0.05 (5%) or less is usually enough to claim that your results are repeatable. However, there’s another way to test the validity of your results: Bayesian Hypothesis testing. This type of testing gives you another way to test the strength of your results.
Traditional testing (the type you probably came across in elementary stats or AP stats) is called Non-Bayesian. It is how often an outcome happens over repeated runs of the experiment. It’s an objective view of whether an experiment is repeatable. Bayesian hypothesis testing is a subjective view of the same thing. It takes into account how much faith you have in your results. In other words, would you wager money on the outcome of your experiment?
Differences Between Traditional and Bayesian Hypothesis Testing.
Traditional testing (Non Bayesian) requires you to repeat sampling over and over, while Bayesian testing does not. The main different between the two is in the first step of testing: stating a probability model. In Bayesian testing you add prior knowledge to this step. It also requires use of a posterior probability , which is the conditional probability given to a random event after all the evidence is considered.
Arguments for Bayesian Testing.
Many researchers think that it is a better alternative to traditional testing, because it:
- Includes prior knowledge about the data.
- Takes into account personal beliefs about the results.
Arguments against.
- Including prior data or knowledge isn’t justifiable.
- It is difficult to calculate compared to non-Bayesian testing.
Back to top
Hypothesis Testing Articles
- What is Ad Hoc Testing?
- Composite Hypothesis Test
- What is a Rejection Region?
- What is a Two Tailed Test?
- How to Decide if a Hypothesis Test is a One Tailed Test or a Two Tailed Test.
- How to Decide if a Hypothesis is a Left Tailed Test or a Right-Tailed Test.
- How to State the Null Hypothesis in Statistics.
- How to Find a Critical Value .
- How to Support or Reject a Null Hypothesis.
Specific Tests:
- Brunner Munzel Test (Generalized Wilcoxon Test).
- Chi Square Test for Normality.
- Cochran-Mantel-Haenszel Test.
- Granger Causality Test .
- Hotelling’s T-Squared.
- KPSS Test .
- What is a Likelihood-Ratio Test?
- Log rank test .
- MANCOVA Assumptions.
- MANCOVA Sample Size.
- Marascuilo Procedure
- Rao’s Spacing Test
- Rayleigh test of uniformity.
- Sequential Probability Ratio Test.
- How to Run a Sign Test.
- T Test: one sample.
- T-Test: Two sample .
- Welch’s ANOVA .
- Welch’s Test for Unequal Variances .
- Z-Test: one sample .
- Z Test: Two Proportion.
- Wald Test .
Related Articles:
- What is an Acceptance Region?
- How to Calculate Chebyshev’s Theorem.
- Contrast Analysis
- Decision Rule.
- Degrees of Freedom .
- Directional Test
- False Discovery Rate
- How to calculate the Least Significant Difference.
- Levels in Statistics.
- How to Calculate Margin of Error.
- Mean Difference (Difference in Means)
- The Multiple Testing Problem .
- What is the Neyman-Pearson Lemma?
- What is an Omnibus Test?
- One Sample Median Test .
- How to Find a Sample Size (General Instructions).
- Sig 2(Tailed) meaning in results
- What is a Standardized Test Statistic?
- How to Find Standard Error
- Standardized values: Example.
- How to Calculate a T-Score.
- T-Score Vs. a Z.Score.
- Testing a Single Mean.
- Unequal Sample Sizes.
- Uniformly Most Powerful Tests.
- How to Calculate a Z-Score.
- Research Consultation
- How-to Guides
- People Search
- Library Databases
- Research Guides
- Find Periodicals
- Google Scholar
- Library Map
- Interlibrary Loan - ILL
- Research & Instruction
- Computers and Laptops
- Services For...
- Reserve a Room
- APSU Records Management
- Library Collections
- Digital Collections
- Special Collections
- Veterans' Oral History
- Government Resources
- Subject Librarians
- Library Information
- Woodward Library Society
- New @ Woodward Library
- Celebration of Scholarship
- Join Woodward Library Society
Original Research: Creating a Hypothesis
- Initial Steps
Creating a Hypothesis
- Research Designs and Methods
- Submitting a Research Plan for Review
- Performing the Research
- Analyzing the Data
- Writing the Research Paper

After following the initial steps, the researcher should be able to create a hypothesis that can be tested. A hypothesis is a proposed statement that is intended to explain a theory for why something happens. To create a solid hypothesis, make sure it is not listed as a question, but as a prediction statement. To create a research hypothesis there has to be both a dependent and independent variable, and an expected outcome. Independent variables are what may be changed in the experiment to create an outcome. The dependent variable is what the experiment is intended to measure based on changes made to the independent variable. Defining the expected outcome creates the predictive component of the hypothesis that can be tested. Incorporating these elements into a simple predictive statement ensures that you can determine an outcome from the experiment. Ensure that any variables are taken into consideration, and that the results from the hypothesis are measurable.
Types of Hypotheses
There are many types of hypotheses, but the seven most common are the following:
- Simple Hypothesis - Questions the relationship between the dependent and independent variables.
- Complex Hypothesis - Questions the effect of multiple dependent and independent variables.
- Empirical Hypothesis - Often called a working hypothesis, this question is applied to a specific field when looking for empirical evidence.
- Null Hypothesis - This is used to contradict the expected effect of dependent and independent variables.
- Alternative Hypothesis - Several hypotheses are given, but as the experiment proceeds, the alternative hypothesis is introduced to reflect the conditions of the experiment.
- Logical Hypothesis - These hypotheses are able to be verified using logic.
- Statistical Hypothesis - A hypothesis of this type is one that can be proven using statistical analysis.
For more information about how to create a hypothesis, have a look at the Fundamentals of Research Methodology by Engwa Godwill.
Based on the hypothesis created, the researcher will need to determine the best research design for the experiment.
Health Sciences Librarian

- << Previous: Initial Steps
- Next: Research Designs and Methods >>
- Last Updated: Jul 26, 2023 10:10 AM
- URL: https://libguides.apsu.edu/OriginalResearch
COMMENTS
Developing a hypothesis (with example) Step 1. Ask a question. Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project. Example: Research question.
Present the findings in your results and discussion section. Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps. Table of contents. Step 1: State your null and alternate hypothesis. Step 2: Collect data. Step 3: Perform a statistical test.
Hypothesis testing is a technique that helps scientists, researchers, or for that matter, anyone test the validity of their claims or hypotheses about real-world or real-life events in order to establish new knowledge. Hypothesis testing techniques are often used in statistics and data science to analyze whether the claims about the occurrence of the events are true, whether the results ...
148. 4. Photo by Anna Nekrashevich from Pexels. Hypothesis testing is a common statistical tool used in research and data science to support the certainty of findings. The aim of testing is to answer how probable an apparent effect is detected by chance given a random data sample. This article provides a detailed explanation of the key concepts ...
Steps of Hypothesis Testing. The steps of hypothesis testing typically involve the following process: Formulate Hypotheses: State the null hypothesis and the alternative hypothesis.; Choose Significance Level (α): Select a significance level (α), which determines the threshold for rejecting the null hypothesis.Commonly used significance levels include 0.05 and 0.01.
Hypothesis testing is an indispensable tool in data science, allowing us to make data-driven decisions with confidence. By understanding its principles, conducting tests properly, and considering real-world applications, you can harness the power of hypothesis testing to unlock valuable insights from your data.
1. Introduction to Hypothesis Testing - Definition and significance in research and data analysis. - Brief historical background. 2. Fundamentals of Hypothesis Testing - Null and Alternative…
Hypothesis Testing is a commonly used statistical tool used in research and Data Science to support the certainty of findings. The primary objective of Hypothetical Testing is to answer the probability of an apparent effect being detected by chance given a random data sample. In this blog, we will give you a detailed explanation of Hypothetical ...
Step 5: Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if … then form. The first part of the sentence states the independent variable and the second part states the dependent variable. If a first-year student starts attending more lectures, then their exam scores will improve.
Photo from StepUp Analytics. Hypothesis testing is a method of statistical inference that considers the null hypothesis H₀ vs. the alternative hypothesis Ha, where we are typically looking to assess evidence against H₀. Such a test is used to compare data sets against one another, or compare a data set against some external standard. The former being a two sample test (independent or ...
It tests the null hypothesis that the population variances are equal (called homogeneity of variance or homoscedasticity). Suppose the resulting p-value of Levene's test is less than the significance level (typically 0.05).In that case, the obtained differences in sample variances are unlikely to have occurred based on random sampling from a population with equal variances.
Data analysis: hypothesis testing. Free statement of participation on completion. Making decisions about the world based on data requires a process that bridges the gap between unstructured data and the decision. Statistical hypothesis testing helps decision-making by formulating beliefs about the world, including people, organisations or other ...
Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables. This post provides an overview of statistical hypothesis testing.
1. Step one: Defining the question. The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the 'problem statement'. Defining your objective means coming up with a hypothesis and figuring how to test it.
A good research hypothesis is informed by prior research and guides research design and data analysis, so it is important to understand how a hypothesis is defined and understood by researchers. What is the simple definition of a hypothesis? A hypothesis is a testable prediction about an outcome between two or more variables. It functions as a ...
3. One-Sided vs. Two-Sided Testing. When it's time to test your hypothesis, it's important to leverage the correct testing method. The two most common hypothesis testing methods are one-sided and two-sided tests, or one-tailed and two-tailed tests, respectively. Typically, you'd leverage a one-sided test when you have a strong conviction ...
Choose a statistical test based on the type of data and the hypothesis. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis. The selection depends on data type, distribution, sample size, and whether the hypothesis is one-tailed or two-tailed. Collect Data. Gather the data that will be analyzed in the test.
H 0 (Null Hypothesis): Population parameter =, ≤, ≥ some value. H A (Alternative Hypothesis): Population parameter <, >, ≠ some value. Note that the null hypothesis always contains the equal sign. We interpret the hypotheses as follows: Null hypothesis: The sample data provides no evidence to support some claim being made by an individual.
Image by Author. We reject the null hypothesis(H₀) if the sample mean(x̅ ) lies inside the Critical Region.; We fail to reject the null hypothesis(H₀) if the sample mean(x̅ ) lies outside the Critical Region.; The formulation of the null and alternate hypothesis determines the type of the test and the critical regions' position in the normal distribution.
Table of contents. Step 1: Write your hypotheses and plan your research design. Step 2: Collect data from a sample. Step 3: Summarize your data with descriptive statistics. Step 4: Test hypotheses or make estimates with inferential statistics.
Step 2: State the Alternate Hypothesis. The claim is that the students have above average IQ scores, so: H 1: μ > 100. The fact that we are looking for scores "greater than" a certain point means that this is a one-tailed test. Step 3: Draw a picture to help you visualize the problem. Step 4: State the alpha level.
A hypothesis test consists of five steps: 1. State the hypotheses. State the null and alternative hypotheses. These two hypotheses need to be mutually exclusive, so if one is true then the other must be false. 2. Determine a significance level to use for the hypothesis. Decide on a significance level.
Statistical Hypothesis - A hypothesis of this type is one that can be proven using statistical analysis. For more information about how to create a hypothesis, have a look at the Fundamentals of Research Methodology by Engwa Godwill. Based on the hypothesis created, the researcher will need to determine the best research design for the experiment.